The Atomic Flag
Atomics guarantee two characteristics. On the one hand, they are atomic, on the other, they provide synchronization and order constraints on the program execution.
I introduced in the last post sequential consistency as the default behavior of atomic operations. But what does that mean? You can specify for each atomic operation the memory order. If not specified, std::memory_order_seq_cst is used.
So this piece of code
x.store(1); res= x.load();
is equivalent to the following piece of code.
x.store(1,std::memory_order_seq_cst); res= x.load(std::memory_order_seq_cst);
For simplicity reasons, I will use the first spelling in this post.
std::atomic_flag
std::atomic_flag has a simple interface. Its method clear enables you the set its value to false, with test_and_set back to true. In case you use test_and_set, you get the old value back. To use std::atomic_flag it must be initialized to false with the constant ATOMIC_FLAG_INIT. That is not so thrilling. But std::atomic_flag has two very interesting properties.
std::atomic_flag is
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
- the only lock-free atomic.
- the building block for higher thread abstractions.
The only lock-free atomic? The remaining more powerful atomics can provide their functionality by using a mutex. That is according to the C++ standard. So these atomics have a method is_lock_free to check if the atomic uses a mutex internally. On popular platforms, I always get the answer false. But you should be aware of that.
The interface of a std::atomic_flag is sufficient to build a spinlock. You can protect a critical section similar to a mutex with a spinlock. But the spinlock will not passively wait in opposition to a mutex until it gets it mutex. It will eagerly ask for the critical section. So it saves the expensive context change in the wait state, but it fully utilizes the CPU:
The example shows the implementation of a spinlock with the help of std::atomic_flag.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
// spinLock.cpp #include <atomic> #include <thread> class Spinlock{ std::atomic_flag flag; public: Spinlock(): flag(ATOMIC_FLAG_INIT) {} void lock(){ while( flag.test_and_set() ); } void unlock(){ flag.clear(); } }; Spinlock spin; void workOnResource(){ spin.lock(); // shared resource spin.unlock(); } int main(){ std::thread t(workOnResource); std::thread t2(workOnResource); t.join(); t2.join(); } |
Threads t and t2 (lines 31 and 32) fight for the critical section. For simplicity reasons, the critical section in line 24 consists only of a comment. How does it work? The class Spinlock has – similar to a mutex – the two methods lock and unlock. In addition, Spinlock’s constructor initializes in line 9 the std::atomic_flag to false. Two scenarios can happen if thread t wants to execute the function workOnResource.
First, the thread t gets the lock. So the lock invocation was successful. The lock invocation is successful if the initial value of the flag in line 12 is false. In this case, thread t sets it in an atomic operation to true. That value true is the value the while loop returns to the other thread t2 if it tries to get the lock. So thread t2 is caught in the rat race. Thread t2 cannot set the value of the flag to false. So t2 must eagerly wait until thread t1 executes the unlock method and sets the flag to false (lines 15 – 17).
Second, the thread t don’t get the lock. So we are in scenario 1 with changed roles.
It’s very interesting to compare a spinlock’s active waiting with a mutex’s passive waiting.
Spinlock versus Mutex
What happens to the CPU load if the function workOnRessoucre locks the spinlock for 2 seconds (lines 23 – 25)?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
// spinLockSleep.cpp #include <atomic> #include <thread> class Spinlock{ std::atomic_flag flag; public: Spinlock(): flag(ATOMIC_FLAG_INIT) {} void lock(){ while( flag.test_and_set() ); } void unlock(){ flag.clear(); } }; Spinlock spin; void workOnResource(){ spin.lock(); std::this_thread::sleep_for(std::chrono::milliseconds(2000)); spin.unlock(); } int main(){ std::thread t(workOnResource); std::thread t2(workOnResource); t.join(); t2.join(); } |
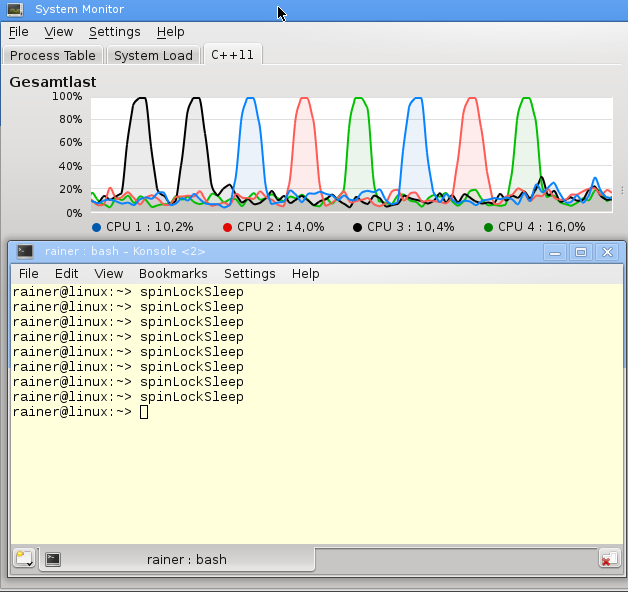
If the theory is right, one of the four cores of my PC must be fully utilized, precisely what you can see in the screenshot.
The screenshot shows nicely that the load of one core gets 100%. But my PC is fair. Each time a different core has to perform the busy waiting.
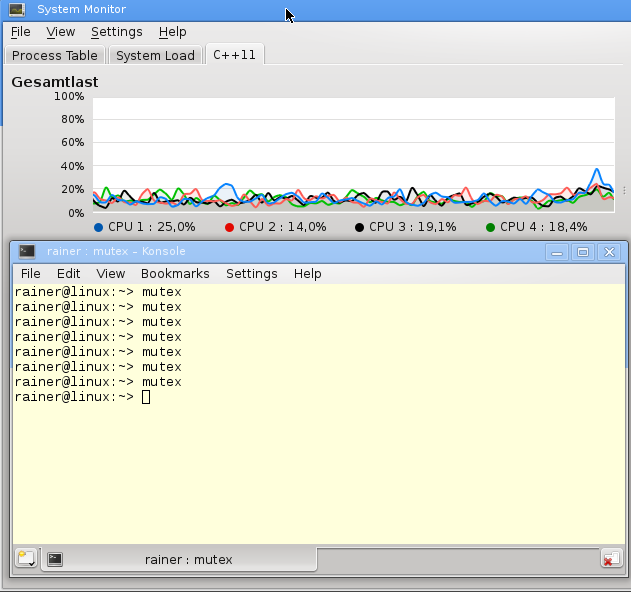
I use in the next concise program a mutex instead of a spinlock.
#include <mutex> #include <thread> std::mutex mut; void workOnResource(){ mut.lock(); std::this_thread::sleep_for(std::chrono::milliseconds(5000)); mut.unlock(); } int main(){ std::thread t(workOnResource); std::thread t2(workOnResource); t.join(); t2.join(); }
Although I execute the program several times, I cannot observe a higher load of the cores.
What’s next?
The next post will be about the class template std::atomic. The various specializations for bools, integral types, and pointers provide a more powerful interface than std::atomic_flag.(Proofreader Alexey Elymanov)
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org





Leave a Reply
Want to join the discussion?Feel free to contribute!