Parallel Algorithms of the STL with the GCC Compiler
GCC supports my favorite C++17 feature: the Standard Template Library (STL) parallel algorithms. I recognized this a few days ago, and I’m happy to write a post about it and share my enthusiasm.
The Microsoft compiler has supported parallel algorithms since its beginning but sadly, neither GCC nor Clang. I have to be precise; GCC 9 allows you to use parallel algorithms. Before I show you examples with performance numbers in my next post, I want to write about the parallel algorithms of the STL and give you the necessary information.
Parallel Algorithms of the Standard Template Library
The Standard Template Library has more than 100 algorithms for searching, counting, and manipulating ranges and their elements. With C++17, 69 get new overloads, and new ones are added. The overloaded and new algorithms can be invoked with a so-called execution policy. Using an execution policy, you can specify whether the algorithm should run sequentially, in parallel, or parallel with vectorization. For using the execution policy, you have to include the header <execution>.
Execution Policy
std::execution::sequenced_policystd::execution::parallel_policystd::execution::parallel_unsequenced_policy
std::execution::seq: runs the program sequentially
std::execution::par: runs the program in parallel on multiple threads
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
std::execution::par_unseq: runs the program in parallel on multiple threads and allows the interleaving of individual loops; permits a vectorized version with SIMD (Single Instruction Multiple Data).
std::execution::par or std::execution::par_unseq allows the algorithm to run parallel or parallel and vectorized. This policy is a permission and not a requirement.
std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9}; // standard sequential sort std::sort(v.begin(), v.end()); // (1) // sequential execution std::sort(std::execution::seq, v.begin(), v.end()); // (2) // permitting parallel execution std::sort(std::execution::par, v.begin(), v.end()); // (3) // permitting parallel and vectorized execution std::sort(std::execution::par_unseq, v.begin(), v.end()); // (4)
std::sort (4). Besides, in C++17, you can specify explicitly whether the sequential (2), parallel (3), or parallel and vectorized (4) version should be used.Parallel and Vectorized Execution
const int SIZE = 8; int vec[] = {1, 2, 3, 4, 5, 6, 7, 8}; int res[] = {0, 0, 0, 0, 0, 0, 0, 0}; int main() { for (int i = 0; i < SIZE; ++i) { res[i] = vec[i]+5; } }
The expression res[i] = vec[i] + 5 is the crucial line in this small example. Thanks to Compiler Explorer, we can look closer at the assembler instructions generated by clang 3.6.
Without Optimization
Here are the assembler instructions. Each addition is done sequentially.

With Maximum Optimization
By using the highest optimization level, -O3, special registers such as xmm0 are used that can hold 128 bits or 4 ints. This special register means that the addition takes place in parallel on four vector elements.

An overload of an algorithm without an execution policy and an overload of an algorithm with a sequential execution policy std::execution::seq differ in one aspect: exceptions.
Exceptions
If an exception occurs during the usage of an algorithm with an execution policy,std::terminate it is called. std::terminate calls the installedstd::terminate_handler. The consequence is that per default std::abort is called, which causes abnormal program termination. The handling of exceptions is the difference between an algorithm’s invocation without an execution policy and an algorithm with a sequential std::execution::seq execution policy. The invocation of the algorithm without an execution policy propagates the exception, and, therefore, the exception can be handled.
With C++17, 69 of the STL algorithms got new overloads, and new algorithms were added.
Algorithms
Here are the 69 algorithms with parallelized versions.

The New Algorithms
The new algorithm in C++17, which are designed for parallel execution, are in the std namespace and need the header <numeric>.
std::exclusive_scan:Applies from the left a binary callable up to the range’s ith (exclusive) element. The left argument of the callable is the previous result—stores intermediate results.std::inclusive_scan: Applies from the left a binary callable up to the range’s ith (inclusive) element. The left argument of the callable is the previous result—stores intermediate results.std::transform_exclusive_scan: First applies a unary callable to the range and then appliesstd::exclusive_scan.std::transform_inclusive_scan: First applies a unary callable to the range and then appliesstd::inclusive_scan.std::reduce: Applies a binary callable to the range.std::transform_reduce: Applies first a unary callable to one or a binary callable to two ranges and thenstd::reduceto the resulting range.
Admittedly this description is not easy to digest, but if you already know std::accumulate and std::partial_sum, the reduce and scan variations should be pretty familiar. std::reduce is the parallel pendant to std::accumulate and scan the parallel pendant to partial_sum. The parallel execution is the reason that std::reduce needs an associative and commutative callable. The corresponding statement holds for the scan variations contrary to the partial_sum variations. To get the full details, visit cppreferenc.com/algorithm.
You may wonder why we need std::reduce for parallel execution because we already have std::accumulate. The reason is that std::accumulate it processes its elements in an order that cannot be parallelized.
std::accumulate versus std::reduce
While std::accumulate processes its elements from left to right, std::reduce and does it in an arbitrary order. Let me start with a small code snippet using std::accumulate and std::reduce. The callable is the lambda function [](int a, int b){ return a * b; }.
std::vector<int> v{1, 2, 3, 4}; std::accumulate(v.begin(), v.end(), 1, [](int a, int b){ return a * b; }); std::reduce(std::execution::par, v.begin(), v.end(), 1 , [](int a, int b){ return a * b; });
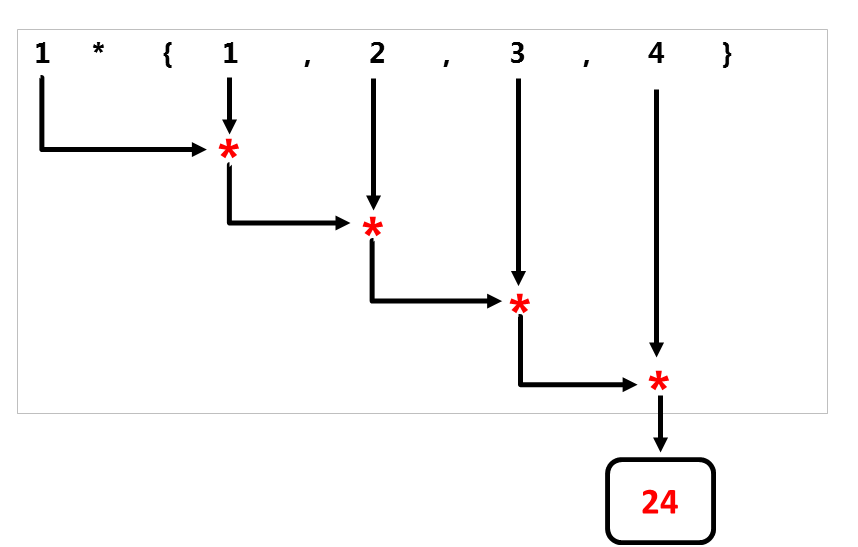
The two following graphs show the different processing strategies of std::accumulate and std::reduce.
std::accumulatestarts at the left and successively applies the binary operator.
- On the contrary,
std::reduceapplies the binary operator in a non-deterministic way.
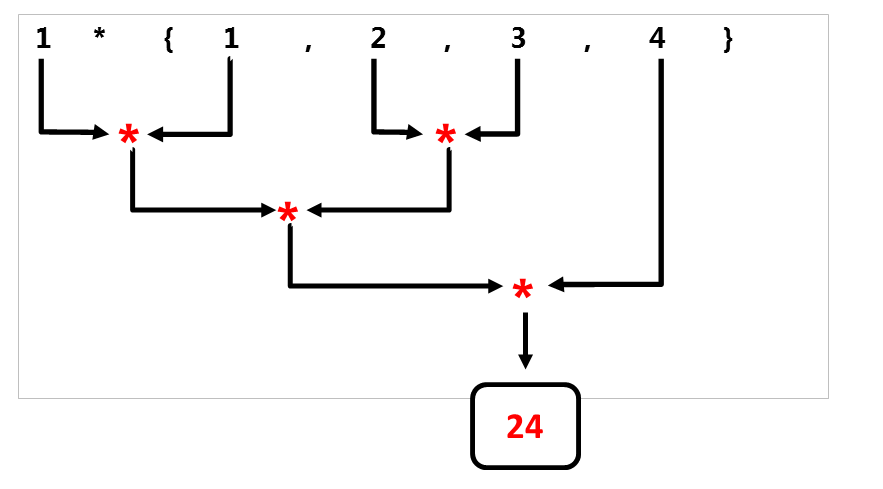
The associativity of the callable allows the std::reduce algorithm to apply the reduction step on arbitrary adjacents pairs of elements. The intermediate results can be computed in an arbitrary order thanks to commutativity.
What’s next?
As promised, my next post uses parallel algorithms of the STL and provides performance numbers for the Microsoft compiler and the GCC.
Five Vouchers for Stephan Roth’s Book “Clean C++20” to Win
I am giving away five vouchers for Stephan Roth’s book “Clean C++20”, sponsored by the book’s publisher Apress. Here is how you can get it: bit.ly/StephanRoth.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org


Leave a Reply
Want to join the discussion?Feel free to contribute!