My Conclusion: Summation of a Vector in three Variants
After I’ve calculated in three different ways the sum of a std::vector I want to draw my conclusions.
The three strategies
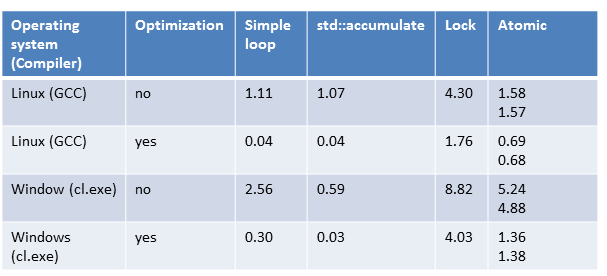
At first, all numbers are in an overview. First, the single-threaded variant; second, the multiple threads with a shared summation variable; last, the multiple threads with minimal synchronization. I have to admit that I was astonished by the last variant.
Single-threaded (1)
Multiple threads with a shared summation variable (2)
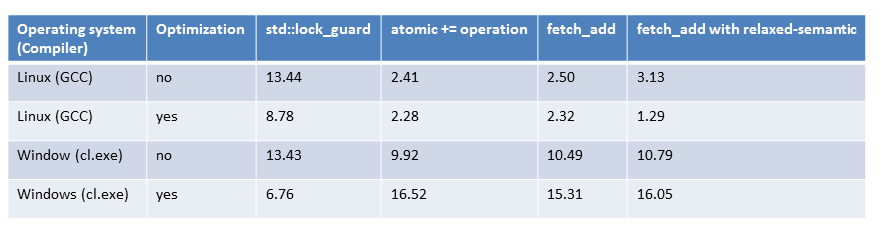
Multiple threads with minimal synchronization (3)
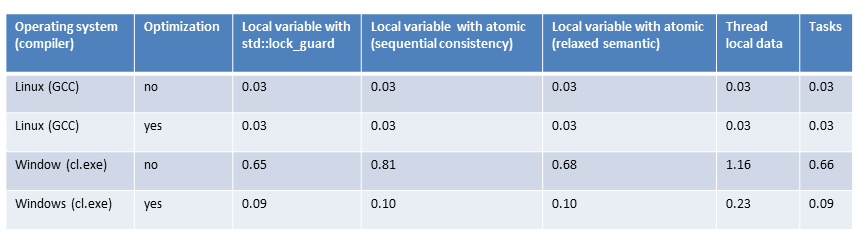
My observations
For simplicity reasons, I will only reason about Linux. Thanks to Andreas Schäfer (https://plus.google.com/u/0/+AndreasSch%C3%A4fer_gentryx), who gave me more profound insight.
Single threaded
The range-based for-loop and the STL algorithm std::accumulate are in the same league. This observation holds for the maximal optimized and non-optimized programs. Interestingly, the maximally optimized version is about 30 times faster than the non-optimized version. The compiler uses for the summation in case of the optimized version vectorized instruction (SSE or AVX). Therefore, the loop counter will be increased by 2 (SSE) or 4 (AVC).
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Multiple threads with a shared summation variable
The synchronization on each access to the shared variable (2) shows on point: Synchronization is expensive. Although I break the sequential consistency with the relaxed semantics, the program is about 40 times slower than the pendants (1) or (3). Not only out of performance reasons, but our goal must also be to minimize the synchronization of the shared variable.
Multiple threads with minimal synchronization
The summation with minimal synchronized threads (4 atomic operations or locks) (3) is hardly faster than the range-based for-loop or std::accumulate (1). However, that holds in the multithreading variant, where four threads can work independently on four cores. That surprised me because I was expecting a nearly fourfold improvement. But what surprised me, even more was that my four cores were not fully utilized.
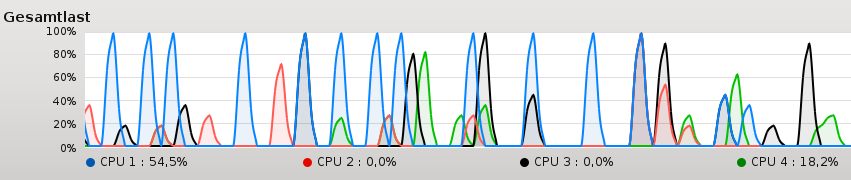
The reason is simple. The cores can’t get the data fast enough from memory. Or to say it the other way around. The memory slows down the cores.
My conclusion
My conclusion from the performance measurements is to use for such a simple operation std::accumulate. That’s for two reasons. First, the performance boost of variant (3) doesn’t justify the expense; second, C++ will have in C++17 a parallel version of std::accumulate. Therefore, switching from the sequential to the parallel version is very easy.
What’s next?
The time library does not belong to the multithreading library, but it’s an essential component of the multithreading capabilities of C++. For example, you have to wait for an absolute time for a lock or put your thread for a relative time to sleep. So in the next post, I will write about time.
.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, and Seeker.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org







Leave a Reply
Want to join the discussion?Feel free to contribute!