
Dining Philosophers Problem II
In the last post “Dining Philosophers Problem I“, Andre Adrian started his analysis of the classical dining philosophers’ problem. Today, he uses atomics, mutexes, and locks.
By Benjamin D. Esham / Wikimedia Commons, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=56559
Let me give you a quick reminder about where Andre’s analysis ended last time.
Still Erroneous Busy Waiting with Resource Hierarchy
// dp_5.cpp #include <iostream> #include <thread> #include <chrono> #include <atomic> int myrand(int min, int max) { return rand()%(max-min)+min; } void lock(std::atomic<int>& m) { while (m) ; // busy waiting m=1; } void unlock(std::atomic<int>& m) { m=0; } void phil(int ph, std::atomic<int>& ma, std::atomic<int>& mb) { while(true) { int duration=myrand(1000, 2000); std::cout<<ph<<" thinks "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); lock(ma); std::cout<<"\t\t"<<ph<<" got ma\n"; std::this_thread::sleep_for(std::chrono::milliseconds(1000)); lock(mb); std::cout<<"\t\t"<<ph<<" got mb\n"; duration=myrand(1000, 2000); std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); unlock(mb); unlock(ma); } } int main() { std::cout<<"dp_5\n"; srand(time(nullptr)); std::atomic<int> m1{0}, m2{0}, m3{0}, m4{0}; std::thread t1([&] {phil(1, m1, m2);}); std::thread t2([&] {phil(2, m2, m3);}); std::thread t3([&] {phil(3, m3, m4);}); std::thread t4([&] {phil(4, m1, m4);}); t1.join(); t2.join(); t3.join(); t4.join(); }
The program looks fine but has a tiny chance of misbehavior. The two operations “is a resource available” and “mark resource as in use” in the lock() function is atomic, but they are still two operations. Between these two operations, the scheduler can place a thread switch. And this thread switches at this most inconvenient time can produce hard-to-find bugs in the program.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Optimized Busy Waiting with Resource Hierarchy
Thankfully all current computers have an atomic operation “test the resource, and if the test is positive, mark resource as in use”. In the programming language C++, the atomic_flag type makes this special “test and set” operation available. The file dp_6.cpp is the first correct solution for the dining philosophers problem:
// dp_6.cpp #include <iostream> #include <thread> #include <chrono> #include <atomic> int myrand(int min, int max) { return rand()%(max-min)+min; } void lock(std::atomic_flag& m) { while (m.test_and_set()) ; // busy waiting } void unlock(std::atomic_flag& m) { m.clear(); } void phil(int ph, std::atomic_flag& ma, std::atomic_flag& mb) { while(true) { int duration=myrand(1000, 2000); std::cout<<ph<<" thinks "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); lock(ma); std::cout<<"\t\t"<<ph<<" got ma\n"; std::this_thread::sleep_for(std::chrono::milliseconds(1000)); lock(mb); std::cout<<"\t\t"<<ph<<" got mb\n"; duration=myrand(1000, 2000); std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); unlock(mb); unlock(ma); } } int main() { std::cout<<"dp_6\n"; srand(time(nullptr)); std::atomic_flag m1, m2, m3, m4; unlock(m1); unlock(m2); unlock(m3); unlock(m4); std::thread t1([&] {phil(1, m1, m2);}); std::thread t2([&] {phil(2, m2, m3);}); std::thread t3([&] {phil(3, m3, m4);}); std::thread t4([&] {phil(4, m1, m4);}); t1.join(); t2.join(); t3.join(); t4.join(); }
atomic_flag spinlock is needed if several threads want to get the same resource.Good low CPU load Busy Waiting with Resource Hierarchy
lock() is a waste of CPU resources. A remedy to this problem is putting a function in this while loop’s body. The sleep_for() function performs waiting in the scheduler. This waiting is much better than waiting in the application. As always, there is a price. The sleep_for() slows down the program’s progress. The file dp_7.cpp is the second correct solution:// dp_7.cpp
void lock(std::atomic_flag& m) { while (m.test_and_set()) std::this_thread::sleep_for(std::chrono::milliseconds(8)); }
std::this_thread::yield() instead of the sleep_for() does not reduce CPU load on the author’s computer. The impact of yield() is implementation-dependent.std::mutex with Resource Hierarchy
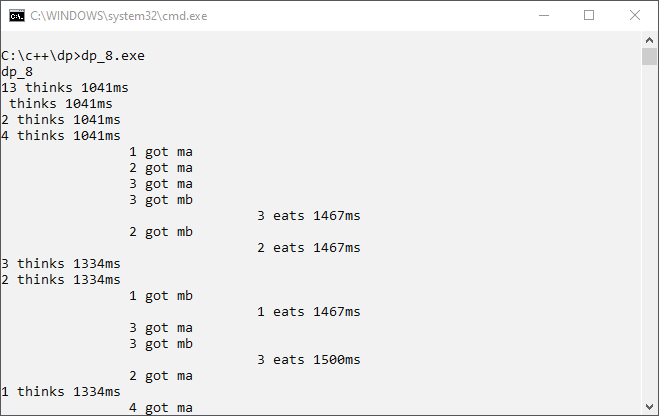
dp_8.cpp shows the mutex solution. Please note the #include <mutex> :// dp_8.cpp #include <iostream> #include <thread> #include <chrono> #include <mutex> int myrand(int min, int max) { return rand()%(max-min)+min; } void phil(int ph, std::mutex& ma, std::mutex& mb) { while(true) { int duration=myrand(1000, 2000); std::cout<<ph<<" thinks "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); ma.lock(); std::cout<<"\t\t"<<ph<<" got ma\n"; std::this_thread::sleep_for(std::chrono::milliseconds(1000)); mb.lock(); std::cout<<"\t\t"<<ph<<" got mb\n"; duration=myrand(1000, 2000); std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); mb.unlock(); // (9) ma.unlock(); } } int main() { std::cout<<"dp_8\n"; srand(time(nullptr)); std::mutex m1, m2, m3, m4; std::thread t1([&] {phil(1, m1, m2);}); std::thread t2([&] {phil(2, m2, m3);}); std::thread t3([&] {phil(3, m3, m4);}); std::thread t4([&] {phil(4, m1, m4);}); t1.join(); t2.join(); t3.join(); t4.join(); }
std::lock_guard with Resource Hierarchy
lock_guard template, we put only the mutex into the lock. The mutex member function lock is automatically called in the locks constructor and unlock its destructor at the end of the scope. unlock is also called if an exception is thrown.
The convenient version is dp_9.cpp:
// dp_9.cpp
void phil(int ph, std::mutex& ma, std::mutex& mb) { while(true) { int duration=myrand(1000, 2000); std::cout<<ph<<" thinks "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); std::lock_guard<std::mutex> ga(ma); std::cout<<"\t\t"<<ph<<" got ma\n"; std::this_thread::sleep_for(std::chrono::milliseconds(1000)); std::lock_guard<std::mutex> gb(mb); std::cout<<"\t\t"<<ph<<" got mb\n"; duration=myrand(1000, 2000); std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); } }
std::lock_guard and Synchronized Output with Resource Hierarchy
lock_guard around every console output. See dp_10.cpp:// dp_10.cpp
std::mutex mo; void phil(int ph, std::mutex& ma, std::mutex& mb) { while(true) { int duration=myrand(1000, 2000); { std::lock_guard<std::mutex> g(mo); std::cout<<ph<<" thinks "<<duration<<"ms\n"; } std::this_thread::sleep_for(std::chrono::milliseconds(duration)); std::lock_guard<std::mutex> ga(ma); { std::lock_guard<std::mutex> g(mo); std::cout<<"\t\t"<<ph<<" got ma\n"; } std::this_thread::sleep_for(std::chrono::milliseconds(1000)); std::lock_guard<std::mutex> gb(mb); { std::lock_guard<std::mutex> g(mo); std::cout<<"\t\t"<<ph<<" got mb\n"; } duration=myrand(1000, 2000); { std::lock_guard<std::mutex> g(mo); std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n"; } std::this_thread::sleep_for(std::chrono::milliseconds(duration)); } }
mo controls the console output resource. Every cout statement is in its block, and the lock_guard() template ensures that console output is no longer garbled.std::lock_guard and Synchronized Output with Resource Hierarchy and a count
dp_11.cpp. This program version counts the number of philosophers threads that are eating simultaneously. Because we have 4 forks, there should be times when 2 philosopher threads eat concurrently. Please note that you need again #include <atomic>. See dp_11.cpp:// dp_11.cpp
std::mutex mo; std::atomic<int> cnt = 0; void phil(int ph, std::mutex& ma, std::mutex& mb) { while(true) { int duration=myrand(1000, 2000); { std::lock_guard<std::mutex> g(mo); std::cout<<ph<<" thinks "<<duration<<"ms\n"; } std::this_thread::sleep_for(std::chrono::milliseconds(duration)); std::lock_guard<std::mutex> ga(ma); { std::lock_guard<std::mutex> g(mo); std::cout<<"\t\t"<<ph<<" got ma\n"; } std::this_thread::sleep_for(std::chrono::milliseconds(1000)); std::lock_guard<std::mutex> gb(mb); { std::lock_guard<std::mutex> g(mo); std::cout<<"\t\t"<<ph<<" got mb\n"; } duration=myrand(1000, 2000); ++cnt; { std::lock_guard<std::mutex> g(mo); std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms "<<cnt<<"\n"; } std::this_thread::sleep_for(std::chrono::milliseconds(duration)); --cnt; } }
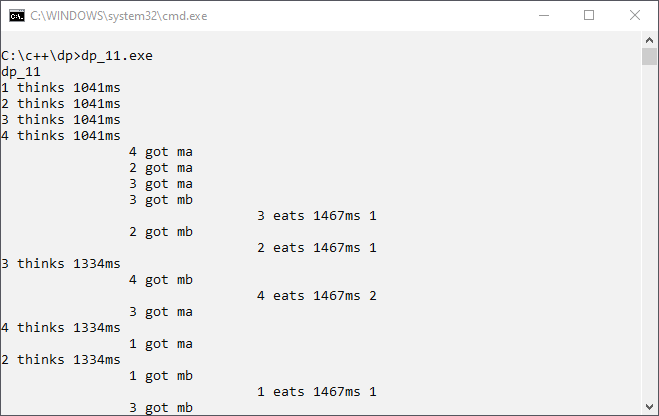
The addition is 1 or 2 at the end of the “eats” logging.
What’s next?
In his next installment of the dining philosophers problem, Andre uses std::unique_lock (C++11), std::scoped_lock (C++17), and std::semaphore (C++20).
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, and Honey Sukesan.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org
Modernes C++ Mentoring,








Leave a Reply
Want to join the discussion?Feel free to contribute!