
C++ Core Guidelines: Concurrency and lock-free Programming
Today, I will finish the rules for concurrency and continue directly with lock-free programming. Yes, you have read it correctly: lock-free programming.

Before I write about lock-free programming in particular, here are the three last rules to concurrency.
- CP.43: Minimize time spent in a critical section
- CP.44: Remember to name your
lock_guards andunique_locks - CP.50: Define a
mutextogether with the data it guards. Usesynchronized_value<T>where possible
I make it short because these rules are quite obvious.
CP.43: Minimize time spent in a critical section
The less time your lock a mutex, the more time other threads can run. Have a look at the notification of a condition variable. If you want to see the entire program, read my previous post C++ Core Guidelines: Be Aware of the Traps of Condition Variables.
void setDataReady(){ std::lock_guard<std::mutex> lck(mutex_); dataReady = true; // (1) std::cout << "Data prepared" << std::endl; condVar.notify_one(); }
The Mutex mutex_ is locked at the beginning and unlocked at the end of the function. This is not necessary. Only the expression dataReady = true (1) has to be protected.
First, std::cout is thread-safe. The C++11 standard guarantees that each character is written in an atomic step and the correct sequence. Second, the notification condVar.notify_one() is thread-safe.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Here is the improved version of the function setDataReady:
void setDataReady(){ { // Don't remove because of the lifetime of the mutex (1) std::lock_guard<std::mutex> lck(mutex_); dataReady = true; } (2) std::cout << "Data prepared" << std::endl; condVar.notify_one(); }
When I teach this rule in my classes to concurrency, often a question arises: Should you document this artificial scope for limiting the lifetime of the std::lock_guard and, therefore, the lifetime of the std::mutex (line (1) and (2))? Most of my students, including me, add a comment to this artificial scope. If not, the maintainer of your code may not be aware that the curly braces in line (1) and line (2) are necessary for controlling the lifetime of the mutex. Ultimately, your maintainer will remove the artificial scope because it seems superfluous, and your code uses the first variant.
CP.44: Remember to name your lock_guards and unique_locks
I was a little astonished to read this rule. Here is an example from the guidelines:
unique_lock<mutex>(m1); lock_guard<mutex> {m2}; lock(m1, m2);
The unique_lock and lock_guard are just temporaries that are created and immediately destroyed. The std::lock_guard or std::unique_lock locks its mutex and its constructor and unlocks it in its destructor. This pattern is called RAII. Read the details here: Garbage Collection: No Thanks.
My small example shows only the conceptual behavior of a std::lock_guard. Its big brotherstd::unique_lock supports more operations.
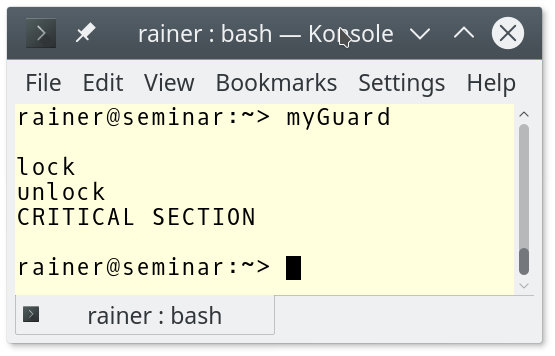
// myGuard.cpp #include <mutex> #include <iostream> template <typename T> class MyGuard{ T& myMutex; public: MyGuard(T& m):myMutex(m){ myMutex.lock(); std::cout << "lock" << std::endl; } ~MyGuard(){ myMutex.unlock(); std::cout << "unlock" << std::endl; } }; int main(){ std::cout << std::endl; std::mutex m; MyGuard<std::mutex> {m}; // (1) std::cout << "CRITICAL SECTION" << std::endl; // (2) std::cout << std::endl; } // (3)
MyGuard calls lock and unlock in its constructor and its destructor. Because of the temporary, the call to the constructor and destructor happens in line (1). In particular, this means that the call of the destructor happens at line (1) and not, as usual, in line (3). Consequently, the critical section in line (2) is executed without synchronization.
This execution of the program shows that the output of “unlock” happens before the output of “CRITICAL SECTION“.
CP.50: Define a mutex together with the data it guards. Use synchronized_value<T> where possible
The central idea is to put your mutex into the data you want to protect. With already standardized C++ it looks like this:
struct Record { std::mutex m; // take this mutex before accessing other members // ... };
With an upcoming standard, it may look like this because synchronized_value<T> is not part of the current C++ standard, but it may become part of an upcoming standard.
class MyClass { struct DataRecord { // ... }; synchronized_value<DataRecord> data; // Protect the data with a mutex };
According to proposal N4033 from Anthony Williams: “The basic idea is that synchronized_value<T> stores a value of type T and a mutex. It then exposes a pointer interface, such that dereferencing the pointer yields a special wrapper type that holds a lock on the mutex, and that can be implicitly converted to T for reading, and which forwards any values assigned to the assignment operator of the underlying T for writing.”
This means that the operation on s in the following code snippet is thread-safe.
synchronized_value<std::string> s; std::string readValue() { return *s; } void setValue(std::string const& newVal) { *s=newVal; } void appendToValue(std::string const& extra) { s->append(extra); }
Now as announced, to something completely different: lock-free programming.
Lock-free programming
First, let me state the most crucial meta-rule to lock-free programming.
Don’t program lock-free
Sure, you don’t believe me, but based on my experience giving many concurrency classes and workshops, this is my first rule. Honestly, I agree with many of the most appreciated C++ experts worldwide. Here are the critical statements and cites from their talks:
- Herb Sutter: Lock-free programming is like playing with knives.
- Anthony Williams: “Lock-free programming is about how to shoot yourself in the foot.“
- Tony Van Eerd: “Lock-free coding is the last thing you want to do.”
- Fedor Pikus: “Writing correct lock-free programs is even harder.“
- Harald Böhm: “The rules are not obvious.“
Here is a picture of the statements and cites:

You still don’t believe me? With C++11, the memory order std::memory_order_consume was defined. Seven years later, the official wording is: “The specification of release-consume ordering is being revised, and the use of memory_order_consume is temporarily discouraged.” (memory_order)
If you know what you do, think about the ABA problem in the guidelines CP.100.
CP.100: Don’t use lock-free programming unless you absolutely have to
The following code snippet from the C++ core guidelines has a bug.
extern atomic<Link*> head; // the shared head of a linked list Link* nh = new Link(data, nullptr); // make a link ready for insertion Link* h = head.load(); // read the shared head of the list do { if (h->data <= data) break; // if so, insert elsewhere nh->next = h; // next element is the previous head } while (!head.compare_exchange_weak(h, nh)); // write nh to head or to h
Find the bug and write me an e-mail. I will mention the best problem analysis in my next post if you like your name.
What’s next?
Of course, I will solve the riddle of the ABA problem in the next post. Afterward, my story with lock-free programming continues.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, and Silviu Ardelean.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org





Leave a Reply
Want to join the discussion?Feel free to contribute!