C++17 – Avoid Copying with std::string_view
The purpose of std::string_view is to avoid copying data already owned by someone else and of which only a non-mutating view is required. So, this post is mainly about performance.
Today, I write about a main feature of C++17.
I assume that you know a little bit about std::string_view. If not, read the previous post C++17 – What’s New in the library first. A C++ string is like a thin wrapper storing data on the heap. Therefore, a memory allocation often kicks in when you deal with C and C++ strings. Let’s have a look.
Small string optimization
You will see in a few lines why I called this paragraph small string optimization.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
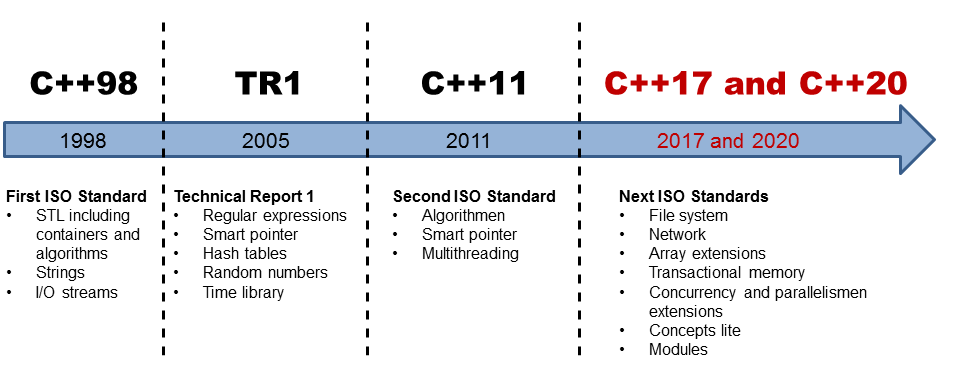
// sso.cpp #include <iostream> #include <string> void* operator new(std::size_t count){ std::cout << " " << count << " bytes" << std::endl; return malloc(count); } void getString(const std::string& str){} int main() { std::cout << std::endl; std::cout << "std::string" << std::endl; std::string small = "0123456789"; std::string substr = small.substr(5); std::cout << " " << substr << std::endl; std::cout << std::endl; std::cout << "getString" << std::endl; getString(small); getString("0123456789"); const char message []= "0123456789"; getString(message); std::cout << std::endl; } |
I overloaded the global operator new in lines 6-9. Therefore, you can see which operation causes a memory allocation. Come on. That’s easy. Lines 19, 20, 28, and 29 cause a memory allocation. Here you have the numbers:
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
What the …? I said. The strings store their data on the heap. But that is only true if the string exceeds an implementation-dependent size. This size for std::string is 15 for MSVC and GCC and 23 for Clang.
That means, on the contrary, small strings are stored directly in the string object. Therefore, no memory allocation is required.
From now on, my strings will always have at least 30 characters. So, I do have not to reason about small string optimization. Let’s start once more but this time with longer strings.
No memory allocation required
Now, std::string_view shines brightly. Contrary to std::string, std::string_view allocates no memory. Here is the proof.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
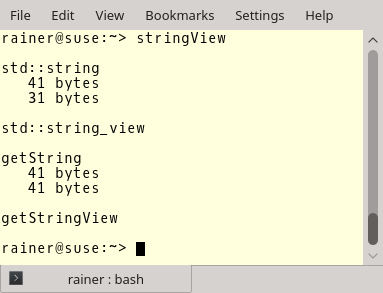
// stringView.cpp #include <cassert> #include <iostream> #include <string> #include <string_view> void* operator new(std::size_t count){ std::cout << " " << count << " bytes" << std::endl; return malloc(count); } void getString(const std::string& str){} void getStringView(std::string_view strView){} int main() { std::cout << std::endl; std::cout << "std::string" << std::endl; std::string large = "0123456789-123456789-123456789-123456789"; std::string substr = large.substr(10); std::cout << std::endl; std::cout << "std::string_view" << std::endl; std::string_view largeStringView{large.c_str(), large.size()}; largeStringView.remove_prefix(10); assert(substr == largeStringView); std::cout << std::endl; std::cout << "getString" << std::endl; getString(large); getString("0123456789-123456789-123456789-123456789"); const char message []= "0123456789-123456789-123456789-123456789"; getString(message); std::cout << std::endl; std::cout << "getStringView" << std::endl; getStringView(large); getStringView("0123456789-123456789-123456789-123456789"); getStringView(message); std::cout << std::endl; } |
Once more. Memory allocations occur in lines 24, 25, 41, and 43. But what happens in the corresponding calls in lines 31, 32, 50, and 51? No memory allocation!
That is impressive. You can imagine this is a performance boost because memory allocation is costly. You can observe this performance boost very well if you build substrings of existing strings.
O(n) versus O(1)
std::string and std::string_view have both a method substr. The method of the std::string returns a substring, but the method of the std::string_view returns a view of a substring. This sounds not so thrilling. But there is a big difference between both methods. std::string::substr has linear complexity. std::string_view::substr has constant complexity. That means that the performance of the operation on the std::string is directly dependent on the size of the substring, but the performance of the operation on the std::string_view is independent of the size of the substring.
Now I’m curious. Let’s make a simple performance comparison.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
// substr.cpp #include <chrono> #include <fstream> #include <iostream> #include <random> #include <sstream> #include <string> #include <vector> #include <string_view> static const int count = 30; static const int access = 10000000; int main(){ std::cout << std::endl; std::ifstream inFile("grimm.txt"); std::stringstream strStream; strStream << inFile.rdbuf(); std::string grimmsTales = strStream.str(); size_t size = grimmsTales.size(); std::cout << "Grimms' Fairy Tales size: " << size << std::endl; std::cout << std::endl; // random values std::random_device seed; std::mt19937 engine(seed()); std::uniform_int_distribution<> uniformDist(0, size - count - 2); std::vector<int> randValues; for (auto i = 0; i < access; ++i) randValues.push_back(uniformDist(engine)); auto start = std::chrono::steady_clock::now(); for (auto i = 0; i < access; ++i ) { grimmsTales.substr(randValues[i], count); } std::chrono::duration<double> durString= std::chrono::steady_clock::now() - start; std::cout << "std::string::substr: " << durString.count() << " seconds" << std::endl; std::string_view grimmsTalesView{grimmsTales.c_str(), size}; start = std::chrono::steady_clock::now(); for (auto i = 0; i < access; ++i ) { grimmsTalesView.substr(randValues[i], count); } std::chrono::duration<double> durStringView= std::chrono::steady_clock::now() - start; std::cout << "std::string_view::substr: " << durStringView.count() << " seconds" << std::endl; std::cout << std::endl; std::cout << "durString.count()/durStringView.count(): " << durString.count()/durStringView.count() << std::endl; std::cout << std::endl; } |
Before I present the numbers, let me say a few words about my performance test. The key idea of the performance test is to read in a large file as a std::string and create a lot of substrings with std::string and std::string_view. I’m precisely interested in how long this creation of substrings will take.
I used “Grimm’s Fairy Tales” as my long file. What else should I use? The string grimmTales (line 24) has the content of the file. I fill the std::vector<int> in line 37 with access number (10’000’000) of values in the range [0, size – count – 2] (line 34). Now the performance test starts. I create in lines 39 to 41 access substrings of the fixed-length count. The count is 30. Therefore, no small string optimization kicks in. I do the same in lines 47 to 49 with the std::string_view.
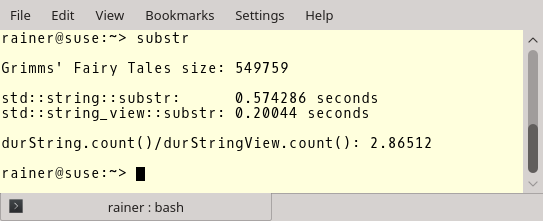
Here are the numbers. You see the length of the file, the numbers for std::string::substr and std::string_view::substr, and the ratio between both. I used GCC 6.3.0 as the compiler.
Size 30
Only out of curiosity. The numbers without optimization.
But now to the more critical numbers. GCC with complete optimization.
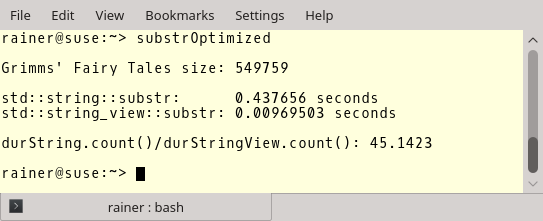
The optimization makes no big difference in the case of std::string but a significant difference in the case of std::string_view. Making a substring with std::string_view is about 45 times faster than using std::string. If that is not a reason to use std::string_view?
Different sizes
Now I’m becoming more curious. What will happen if I play with the size count of the substring? Of course, all numbers are with maximum optimization. I rounded them to the 3rd decimal place.
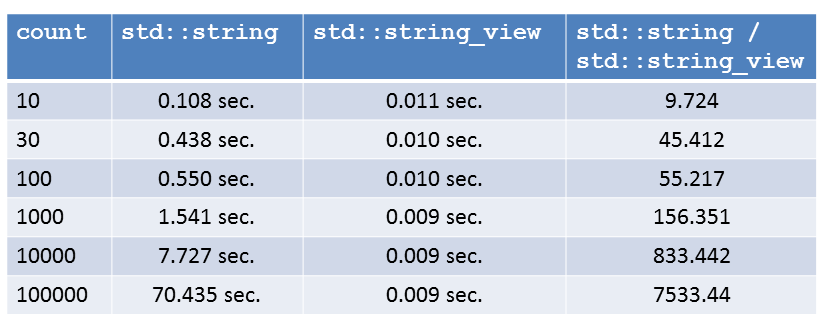
I’m not astonished; the numbers reflect the complexity guarantees of std::string::substr versus std::string_view::substr. The complexity of the first is linearly dependent on the substring’s size; the second is independent of the size of the substring. In the end, the std::string_view drastically outperforms std::string.
What’s next?
There is more to write about std::any, std::optional, and std::variant. Wait for the next post.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, and Seeker.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org



Leave a Reply
Want to join the discussion?Feel free to contribute!