Associative Containers – A simple Performance Comparison
Before I take a deeper look insight the interface of the hash tables – officially called unordered associative containers – I will first compare the performance of the associative containers. The best candidates are std::unordered_map and the ordered pendant std::map because both are used most frequently.
Admittedly, the eight variations of associative containers are a little bit confusing. In addition, the name component unordered the new ones is not easy to read and write. The reason for the special names is easily explained. On the one hand, the unordered associative containers were too late for the C++98 standard. On the other hand, they were missed so severely that most architectures implemented them by themself. Therefore, simple names have already been used, and the C++ standardization committee has to use more elaborated names. But it is very nice that the names of the unordered associative containers follow a simple pattern. I presented the pattern in the post Hash tables.
std::map versus std::unordered_map
For my simple performance comparison, I put a lot of arbitrary values into a std::map and std::unorderd_map and measured and compared their performance. Precisely this is done in my program.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
// associativeCompare.cpp #include <chrono> #include <iostream> #include <map> #include <random> #include <unordered_map> static const long long mapSize= 10000000; static const long long accSize= 1000000; int main(){ std::cout << std::endl; std::map<int,int> myMap; std::unordered_map<int,int> myHash; for ( long long i=0; i < mapSize; ++i ){ myMap[i]=i; myHash[i]= i; } std::vector<int> randValues; randValues.reserve(accSize); // random values std::random_device seed; std::mt19937 engine(seed()); std::uniform_int_distribution<> uniformDist(0,mapSize); for ( long long i=0 ; i< accSize ; ++i) randValues.push_back(uniformDist(engine)); auto start = std::chrono::system_clock::now(); for ( long long i=0; i < accSize; ++i){ myMap[randValues[i]]; } std::chrono::duration<double> dur= std::chrono::system_clock::now() - start; std::cout << "time for std::map: " << dur.count() << " seconds" << std::endl; auto start2 = std::chrono::system_clock::now(); for ( long long i=0; i < accSize; ++i){ myHash[randValues[i]]; } std::chrono::duration<double> dur2= std::chrono::system_clock::now() - start2; std::cout << "time for std::unordered_map: " << dur2.count() << " seconds" << std::endl; std::cout << std::endl; } |
I fill in lines 19 -22 a std::map (line 20) and a std::unordered_map (line 21) with mapSize key/values pairs. mapSize is ten million. Then I create a std::vector with one million arbitrary elements between 0 and mapSize. The random number generator engine(seed()) (line 29) initialized by the seed creates the values. I use in line 30 the random number generator engine in combination with the random number distribution unformDist: uniformDist(engine). Of course, uniformDist guarantees the uniform distribution of the values. Ultimately, randValues has one million arbitrarily created elements between 0 and 10 million that are uniformly distributed. These one million elements are the keys for which I’m interested in the values from std::map and the std::unordered_map.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
How do they compare to each other?
Without optimization
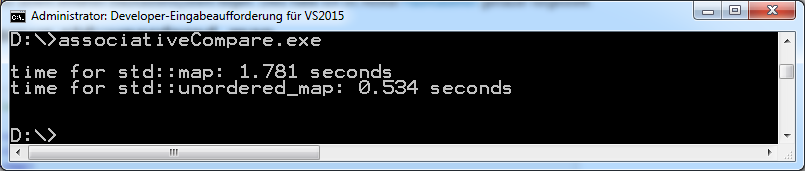
At first, I compile the program without optimization. I use the current Microsoft Visual 15 C++ compiler and GCC 4.8. Here are the numbers.
Microsoft Visual C++ Compiler
GCC Compiler
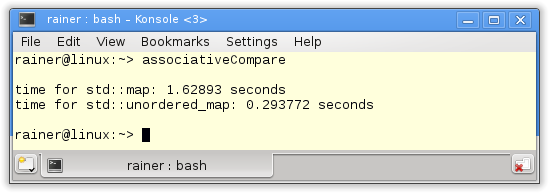
The performance differences are significant. The std::unordered_map is about three times faster on Windows and about five times faster on Linux. I stop here with my reasoning because the executables run on different PC.
Now I’m curious about the optimized versions.
Maximum optimization
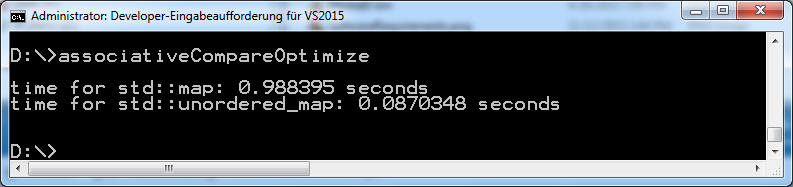
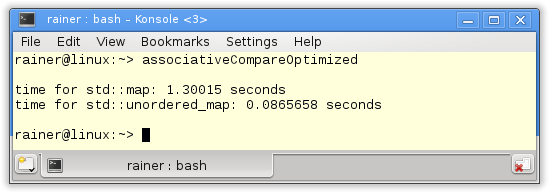
To compile the program with maximum optimization, I use the cl.exe compiler, the flag Ox; in the case of the g++ compiler, the flag O3. The performance differences from the non-optimized versions are very impressive.
Microsoft Visual C++
By compiling with full optimization, the access time to the std::map becomes about two times faster, and the access time to the std::unorderd_map becomes about six times faster. Therefore, the std::unorderd_map is 11 times faster than the std::map.
GCC Compiler
The performance difference is not so dramatic in the case of the GCC compiler. Therefore, the optimized access with std::map is about 20% faster, but the access time of std::unordered_map is about six times faster.
I present them once more in a simple table to whom – like me – is lost with so many numbers.
The raw numbers
For simplicity reasons, I rounded the value to 3 decimal places. The last two columns show the maximum optimized programs with (cl.exe /Ox) on Windows and (g++ -O3) on Linux.

What’s next?
In the post Hash tables, I said quite imprecise that the unordered associative containers have a similar interface as the ordered associative containers. That is not true. The unordered associative containers have a more powerful interface than the ordered pendants. E.g., you can adjust the hash function or the distribution of the hash values to their buckets. As ever, the details will follow in the next post.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, and Seeker.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org







Leave a Reply
Want to join the discussion?Feel free to contribute!