Dealing with Sharing
If you don’t share, no data races can happen. Not sharing means that your thread works on local variables. This can be achieved by copying the value, using thread-specific storage, or transferring the result of a thread to its associated future via a protected data channel.
The patterns in this section are quite obvious, but I will present them with a short explanation for completeness. Let me start with Copied Value.
Copied Value
If a thread gets its arguments by copy and not by reference, there is no need to synchronize access to any data. No data races and no lifetime issues are possible.
Data Races with References
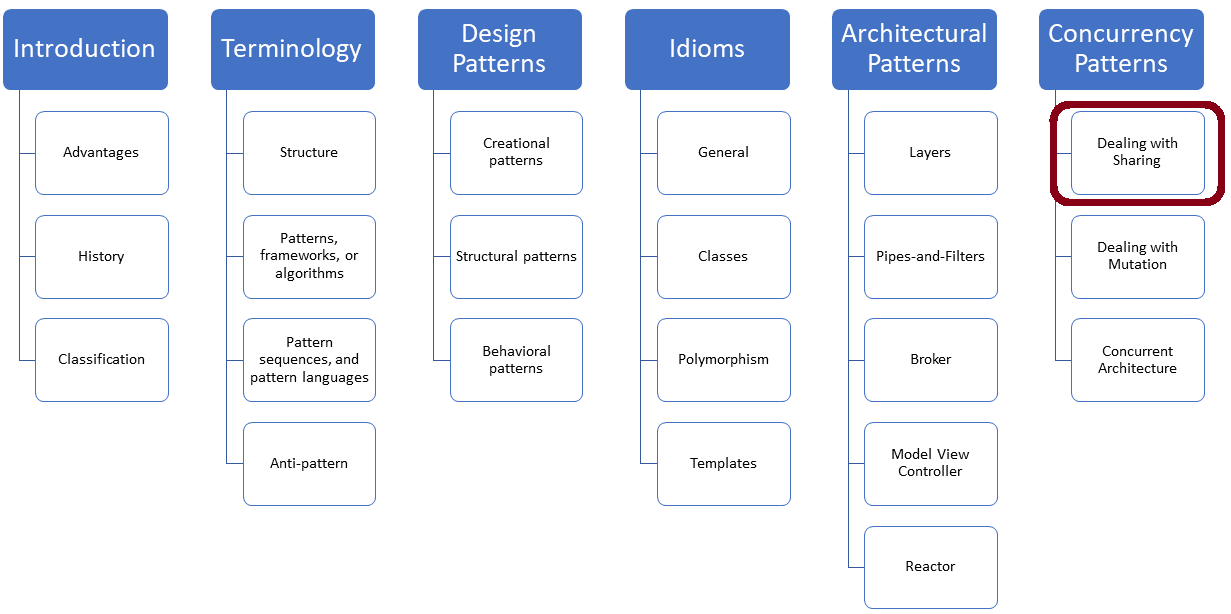
The following program creates three threads. One thread gets its argument by copy, the other by reference, and the last by constant reference.
// copiedValueDataRace.cpp #include <functional> #include <iostream> #include <string> #include <thread> using namespace std::chrono_literals; void byCopy(bool b){ std::this_thread::sleep_for(1ms); // (1) std::cout << "byCopy: " << b << '\n'; } void byReference(bool& b){ std::this_thread::sleep_for(1ms); // (2) std::cout << "byReference: " << b << '\n'; } void byConstReference(const bool& b){ std::this_thread::sleep_for(1ms); // (3) std::cout << "byConstReference: " << b << '\n'; } int main(){ std::cout << std::boolalpha << '\n'; bool shared{false}; std::thread t1(byCopy, shared); std::thread t2(byReference, std::ref(shared)); std::thread t3(byConstReference, std::cref(shared)); shared = true; t1.join(); t2.join(); t3.join(); std::cout << '\n'; }
Each thread sleeps for one millisecond (lines 1, 2, and 3) before displaying the boolean value. Only the thread t1 has a local copy of the boolean and has, therefore, no data race. The program’s output shows that the boolean values of threads t2 and t3 are modified without synchronization.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
You may think that the thread t3 in the previous example copiedValueDataRace.cpp can just be replaced with std::thread t3(byConstReference, shared). The program compiles and runs, but what seems like a reference is a copy. The reason is that the type traits function std::decay is applied to each thread argument. std::decay performs lvalue-to-rvalue, array-to-pointer, and function-to-pointer implicit conversions to its type T. In particular, it invokes, in this case, the type traits function std::remove_reference on the type T.
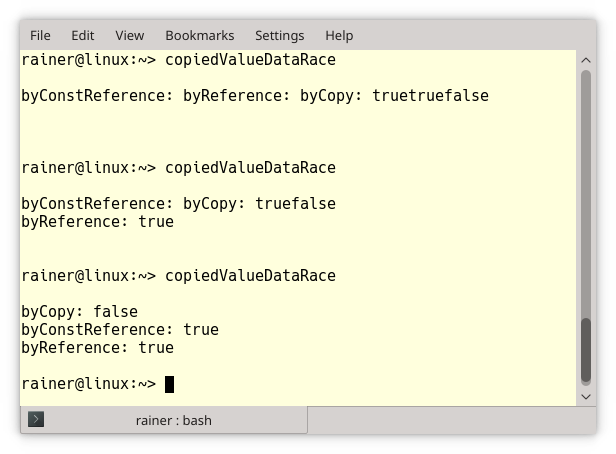
The following program perConstReference.cpp uses a non-copyable type NonCopyableClass.
// perConstReference.cpp #include <thread> class NonCopyableClass{ public: // the compiler generated default constructor NonCopyableClass() = default; // disallow copying NonCopyableClass& operator = (const NonCopyableClass&) = delete; NonCopyableClass (const NonCopyableClass&) = delete; }; void perConstReference(const NonCopyableClass& nonCopy){} int main(){ NonCopyableClass nonCopy; // (1) perConstReference(nonCopy); // (2) std::thread t(perConstReference, nonCopy); // (3) t.join(); }
The object nonCopy (line 1) is not copyable. This is fine if I invoke the function perConstReference with the argument nonCopy (line 2) because the function accepts its argument per constant reference. Using the same function in the thread t (line 3) causes GCC to generate a verbose compiler error with more than 300 lines:

The error message’s essential part is in the middle of the screenshot in red rounded rectangle: “error: use of deleted function”. The copy-constructor of the class NonCopyableClass is not available.
When you borrow something, you have to ensure that the underlying value is still available when you use it.
Lifetime Issues with References
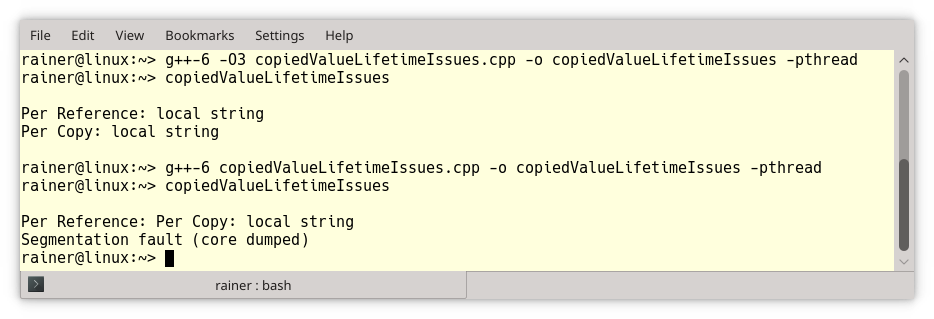
If a thread uses its argument by reference and you detach the thread, you have to be extremely careful. The small program copiedValueLifetimeIssues.cpp has undefined behavior.
// copiedValueLifetimeIssues.cpp #include <iostream> #include <string> #include <thread> void executeTwoThreads(){ // (1) const std::string localString("local string"); // (4) std::thread t1([localString]{ std::cout << "Per Copy: " << localString << '\n'; }); std::thread t2([&localString]{ std::cout << "Per Reference: " << localString << '\n'; }); t1.detach(); // (2) t2.detach(); // (3) } using namespace std::chrono_literals; int main(){ std::cout << '\n'; executeTwoThreads(); std::this_thread::sleep_for(1s); std::cout << '\n'; }
executeTwoThreads (lines 1) starts two threads. Both threads are detached (lines 2 and 3) and print the local variable localString (line 4). The first thread captures the local variable by copy, and the second the local variable by reference. For simplicity reasons, I used a lambda expression in both cases to bind the arguments. Because the executeTwoThreads function doesn’t wait until the two threads have finished, the thread t2 refers to the local string, which is bound to the lifetime of the invoking function. This causes undefined behavior. Curiously, with GCC the maximum optimized executable -O3 seems to work, and the non-optimized executable crashes.
Thanks to thread-local storage, a thread can easily work on its data.
Thread-Specific Storage
Thread-specific or thread-local storage allows multiple threads to use local storage via a global access point. By using the storage specifier thread_local, a variable becomes a thread-local variable. This means you can use the thread-local variable without synchronization.
Assume you want to calculate the sum of all elements of a vector randValues. Doing it with a range-based for-loop is straightforward.
unsigned long long sum{}; for (auto n: randValues) sum += n;
But your PC has four cores. Therefore, you make a concurrent program out of the sequential program:
// threadLocallSummation.cpp #include <atomic> #include <iostream> #include <random> #include <thread> #include <utility> #include <vector> constexpr long long size = 10000000; constexpr long long fir = 2500000; constexpr long long sec = 5000000; constexpr long long thi = 7500000; constexpr long long fou = 10000000; thread_local unsigned long long tmpSum = 0; void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end) { for (auto i = beg; i < end; ++i){ tmpSum += val[i]; } sum.fetch_add(tmpSum); } int main(){ std::cout << '\n'; std::vector<int> randValues; randValues.reserve(size); std::mt19937 engine; std::uniform_int_distribution<> uniformDist(1, 10); for (long long i = 0; i < size; ++i) randValues.push_back(uniformDist(engine)); std::atomic<unsigned long long> sum{}; std::thread t1(sumUp, std::ref(sum), std::ref(randValues), 0, fir); std::thread t2(sumUp, std::ref(sum), std::ref(randValues), fir, sec); std::thread t3(sumUp, std::ref(sum), std::ref(randValues), sec, thi); std::thread t4(sumUp, std::ref(sum), std::ref(randValues), thi, fou); t1.join(); t2.join(); t3.join(); t4.join(); std::cout << "Result: " << sum << '\n'; std::cout << '\n'; }
You put the range-based for-loop into a function and let each thread calculate a fourth of the sum in the thread_local variable tmpSum. The line sum.fetch_add(tmpSum) (line 1) finally sums up all values in the atomic sum. You can read more about thread_local storage in my previous post “Thread-Local Data“.
Promises and futures share a protected data channel.
Future
C++11 provides futures and promise in three flavors: std::async, std::packaged_task, and the pair std::promise and std::future. The future is a read-only placeholder for the value that a promise sets. From the synchronization perspective, a promise/future pair’s critical property is that a protected data channel connects both. There are a few decisions to make when implementing a future.
- A future can ask for its value implicitly or explicitly with the
getcall, such as in C++. - A future can eagerly or lazily start the computation. Only the promise
std::asyncsupports lazy evaluation via launch policies.
auto lazyOrEager = std::async([]{ return "LazyOrEager"; }); auto lazy = std::async(std::launch::deferred, []{ return "Lazy"; }); auto eager = std::async(std::launch::async, []{ return "Eager"; });
lazyOrEager.get(); lazy.get(); eager.get();
If I don’t specify a launch policy, it’s up to the system to start the job eager or lazy. Using the launch policy std::launch::async, a new thread is created, and the promise immediately starts its job. This
is in contrast to the launch policy std::launch::deferred. The call eager.get() starts the promise. Additionally, the promise is executed in the thread requesting the result with get.
If you want to read more about futures in C++, read the following post: “Asynchronous Function Calls“.
What’s Next?
No data race can happen if you don’t write and read data concurrently. In my next, I will write about patterns that help you to protect against mutation.
{module title=”Marketing”}
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery,and Matt Godbolt.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org
Modernes C++ Mentoring,

Leave a Reply
Want to join the discussion?Feel free to contribute!