Performance of the Parallel STL Algorithms
In my last post, “Parallel Algorithms of the STL with the GCC Compiler“, I presented the necessary theory about the C++17 algorithm. Today, I made a performance test using the Microsoft and GCC compiler to answer the simple question: Does the execution policy pay off?
The reason for the short detour about my template post is the following. I recognized that GCC supports my favorite C++17 feature: the parallel algorithms of the Standard Template Library. I present in this post the brand-new GCC 11.1, but a GCC 9 should also be acceptable. You have to install a few additional libraries to use the parallel STL algorithms with the GCC.
Threading Building Blocks
The GCC uses the Intel Thread Building blocks (TBB) under the hood. The TBB is a C++ template library developed by Intel for parallel programming on multi-core processors.
To be precise, you need TBB 2018 version or higher. When I installed the developer package of the TBB on my Linux desktop (Suse), the package manager also chose the TBB memory allocator. Using the TBB is easy. You have to link against the TBB using the flag -ltbb.

Now, I’m prepared to take my next steps with parallel algorithms. Here are the first numbers using the Microsoft Compiler 19.16 and GCC 11.1.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Performance Numbers with the Microsoft Compiler and the GCC Compiler
The following program parallelSTLPerformance.cpp calculates the tangents with the sequential (1), parallel (2), and parallel and vectorized (3) execution policy.
// parallelSTLPerformance.cpp #include <algorithm> #include <cmath> #include <chrono> #include <execution> #include <iostream> #include <random> #include <string> #include <vector> constexpr long long size = 500'000'000; const double pi = std::acos(-1); template <typename Func> void getExecutionTime(const std::string& title, Func func){ // (4) const auto sta = std::chrono::steady_clock::now(); func(); // (5) const std::chrono::duration<double> dur = std::chrono::steady_clock::now() - sta; std::cout << title << ": " << dur.count() << " sec. " << std::endl; } int main(){ std::cout << '\n'; std::vector<double> randValues; randValues.reserve(size); std::mt19937 engine; std::uniform_real_distribution<> uniformDist(0, pi / 2); for (long long i = 0 ; i < size ; ++i) randValues.push_back(uniformDist(engine)); std::vector<double> workVec(randValues); getExecutionTime("std::execution::seq", [workVec]() mutable { // (6) std::transform(std::execution::seq, workVec.begin(), workVec.end(), // (1) workVec.begin(), [](double arg){ return std::tan(arg); } ); }); getExecutionTime("std::execution::par", [workVec]() mutable { // (7) std::transform(std::execution::par, workVec.begin(), workVec.end(), // (2) workVec.begin(), [](double arg){ return std::tan(arg); } ); }); getExecutionTime("std::execution::par_unseq", [workVec]() mutable { // (8) std::transform(std::execution::par_unseq, workVec.begin(), workVec.end(), // (3) workVec.begin(), [](double arg){ return std::tan(arg); } ); }); std::cout << '\n'; }
First, the vector randValues is filled with 500 million numbers from the half-open interval [0, pi / 2 [. The function template getExecutionTime (4) gets the name of the execution policy, and the lambda function executes the lambda function (5) and shows the execution time. There is one particular point about the three lambda functions ((6), (7), and (8)) used in this program. They are declared mutable. This is necessary because the lambda functions modify their argument workVec. Lambda functions are, per default, constant. If a lambda function wants to change its values, it has to be declared mutable.
Let me start with the windows performance numbers. But before I do that, I have to make a short disclaimer.
Disclaimer
I explicitly want to emphasize this. I don’t want to compare Windows and Linux because both computers run Windows, and Linux has different capabilities. These performance numbers should only give you a gut feeling. If you want the numbers for your system, you must repeat the test.
I use maximum optimization on Windows and Linux. This means for Windows, the flag /O2 and on Linux, the flag -O3.
To make it short. I’m keen to know if the parallel execution of the STL algorithms pays and to what extent. My main focus is the relative performance of sequential and parallel execution.
Windows
My windows laptop has eight logical cores, but the parallel execution is more than ten times faster.
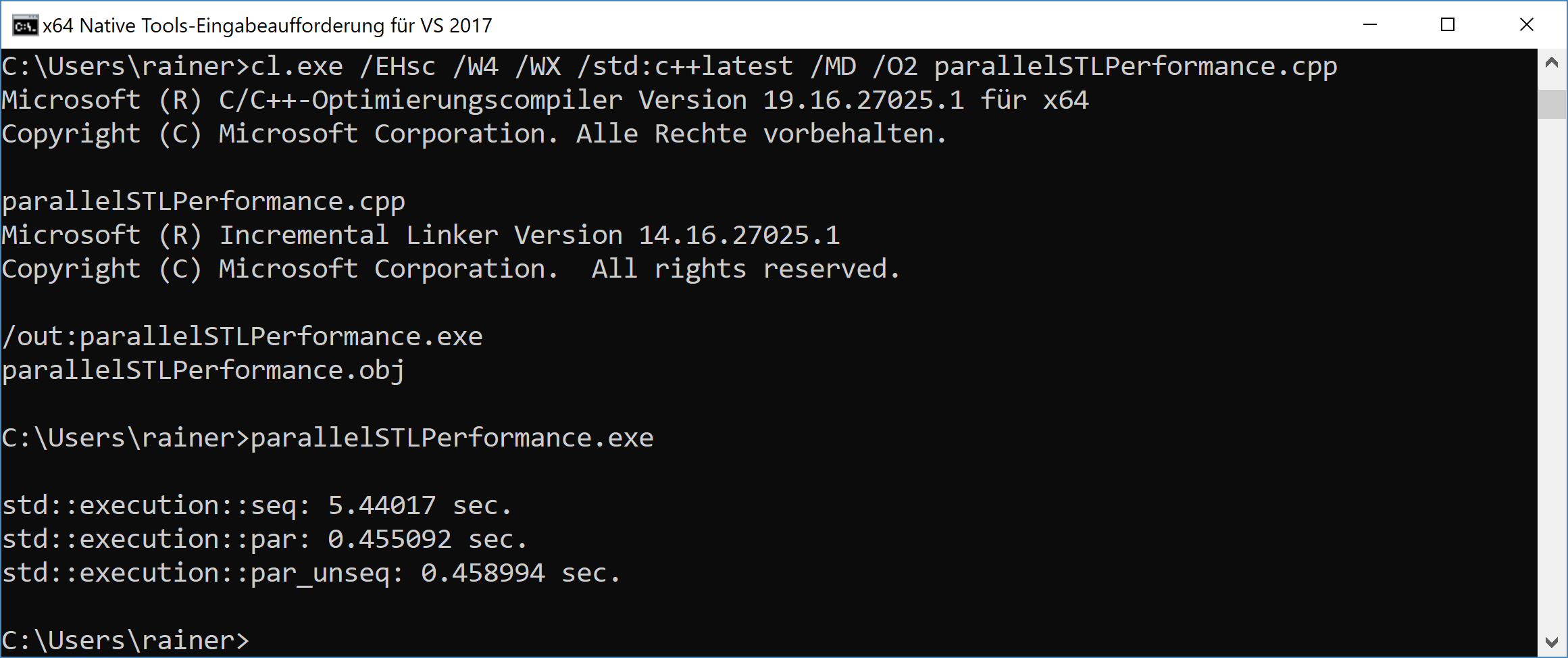
The numbers for the parallel and the parallel and vectorized execution are in the same ballpark. Here is the explanation for the Visual C++ Team Blog: Using C++17 Parallel Algorithms for Better Performance: Note that the Visual C++ implementation implements the parallel and parallel unsequenced policies the same way, so you should not expect better performance for using par_unseq on our implementation, but implementations may exist that can use that additional freedom someday.
Linux
My Linux computer has only four cores. Here are the numbers.
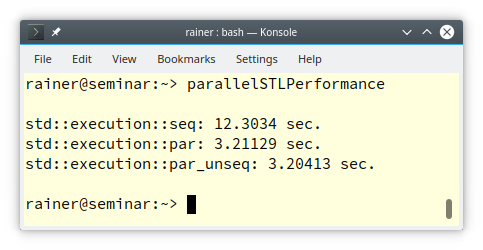
The numbers are as expected. I have four cores, and the parallel execution is about four times faster than the sequential execution. The performance numbers of the parallel and vectorized version and the parallel version are in the same ballpark. Therefore, I assume that the GCC compiler uses the same strategy as the Windows compiler. When I ask for parallel and vectorized execution by using the execution policy std::execute::par_unseqI get the parallel execution policy (std::execute::par). This behavior is according to the C++17 standard because the execution policies are only a hint for the compiler.
To my knowledge, neither the Windows compiler nor the GCC compiler supports the parallel and vectorized execution of parallel STL algorithms. When you want to see the parallel and vectorized algorithms in action, Nvidias STL implementation Thrust may be an ideal candidate. For further information, read the following Nvidia post: “C++ Standard Parallelism“.
What’s next?
After this C++17 detour, I return to my original path: templates. In my next post, I will dive deeper into templates and write about template instantiation.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, and Honey Sukesan.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org
Modernes C++ Mentoring,


Leave a Reply
Want to join the discussion?Feel free to contribute!