
C++ Core Guidelines: Rules about Performance
Before I write about the rules of performance, I will do a straightforward job. Accessing the elements of a container one by one.
Here is the last rule for arithmetic.
ES.107: Don’t use unsigned for subscripts, prefer gsl::index
Did I say that this is a simple job? Honestly, this was a lie. See what can go wrong. Here is an example of a std::vector.
vector<int> vec = /*...*/; for (int i = 0; i < vec.size(); i += 2) // may not be big enough (2) cout << vec[i] << '\n'; for (unsigned i = 0; i < vec.size(); i += 2) // risk wraparound (3) cout << vec[i] << '\n'; for (auto i = 0; i < vec.size(); i += 2) // may not be big enough (2) cout << vec[i] << '\n'; for (vector<int>::size_type i = 0; i < vec.size(); i += 2) // verbose (1) cout << vec[i] << '\n'; for (auto i = vec.size()-1; i >= 0; i -= 2) // bug (4) cout << vec[i] << '\n'; for (int i = vec.size()-1; i >= 0; i -= 2) // may not be big enough (2) cout << vec[i] << '\n';
Scary? Right! Only line (1) is correct. It may happen in line (2) that the variable i is too small. The result may be an overflow. This will not hold for line (3) because i is unsigned. Instead of an overflow, you will get a modulo operation. In my last post, I wrote about this nice effect: C++ Core Guidelines: Rules to Statements and Arithmetic. To be more specific, it was ruled ES.106.
Line 4 is left. This is my favorite one. What is the problem? The problem is that vec.size() is of type std::size_t. std::size_t is an unsigned type and can not represent negative numbers. Imagine what would happen if the vector was empty. This means that vec.size() -1 is –1. The result is that we get the maximum value of type std::size_t.
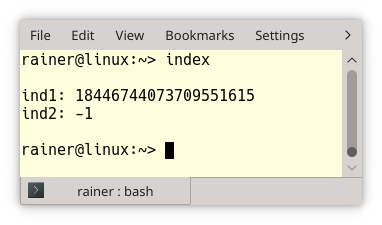
The program index.cpp shows this strange behavior.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
// index.cpp #include <iostream> #include <vector> int main(){ std::cout << std::endl; std::vector<int> vec{}; auto ind1 = vec.size() - 1 ; int ind2 = vec.size() -1 ; std::cout << "ind1: " << ind1 << std::endl; std::cout << "ind2: " << ind2 << std::endl; std::cout << std::endl; }
And here is the output:
The guidelines suggest that the variable i should be of type gsl::index.
for (gsl::index i = 0; i < vec.size(); i += 2) // ok cout << vec[i] << '\n'; for (gsl::index i = vec.size()-1; i >= 0; i -= 2) // ok cout << vec[i] << '\n';
If this is not an option, use the type std::vector<int>::size_type for i.
Performance is the domain of C++! Right? Therefore I was pretty curious to write about the rules for performance. But this is hardly possible because most of the rules lack beef. They consist of a title and a reason. Sometimes even the reason is missing.
Anyway. Here are the first rules:
- Per.1: Don’t optimize without reason
- Per.2: Don’t optimize prematurely
- Per.3: Don’t optimize something that’s not performance critical
- Per.4: Don’t assume that complicated code is necessarily faster than simple code
- Per.5: Don’t assume that low-level code is necessarily faster than high-level code
- Per.6: Don’t make claims about performance without measurements
Instead of writing general remarks to general rules, I will provide a few examples of these rules. Let’s start with rules Per.4, Per.5, and Per.6
Per.4: Don’t assume that complicated code is necessarily faster than simple code
Per.5: Don’t assume that low-level code is necessarily faster than high-level code
Per.6: Don’t make claims about performance without measurements
Before I continue to write, I have to make a disclaimer: I do not recommend using the singleton pattern. I only want to show that complicated and low-level code does not always pay off. To prove my point, I have to measure the performance.
Long ago, I wrote about the thread-safe initialization of the singleton pattern in my post: Thread-safe initialization of a singleton. The key idea of the post was to invoke the singleton pattern 40.000.000 times from four threads and measure the execution time. The singleton pattern will be initialized lazily; therefore, the first call has to initialize it.
I implemented the singleton pattern in various ways. I did it with a std::lock_guard and the function std::call_once in combination with the std::once_flag. I did it with a static variable. I even used atomics and broke the sequential consistency for performance reasons.
To make my pointer clear. I want to show you the most straightforward and challenging implementation.
The easiest implementation is the so-called Meyers singleton. It is thread-safe because the C++11-standard guarantees that a static variable with block scope will be initialized in a thread-safe way.
// singletonMeyers.cpp #include <chrono> #include <iostream> #include <future> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton& getInstance(){ static MySingleton instance; // (1) // volatile int dummy{}; return instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; }; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for (size_t i= 0; i < tenMill; ++i){ MySingleton::getInstance(); // (2) } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; }
Line (1) uses the guarantee of the C++11-runtime that the singleton will be initialized in a thread-safe way. Each of the four threads in the main function invokes 10 million times the singleton inline (2). In total, this makes 40 million calls.
But I can do better. This time I use atomics to make the singleton pattern thread-safe. My implementation is based on the infamous double-checked locking pattern. For the sake of simplicity, I will only show the implementation of the class MySingleton.
class MySingleton{ public: static MySingleton* getInstance(){ MySingleton* sin= instance.load(std::memory_order_acquire); if ( !sin ){ std::lock_guard<std::mutex> myLock(myMutex); sin= instance.load(std::memory_order_relaxed); if( !sin ){ sin= new MySingleton(); instance.store(sin,std::memory_order_release); } } // volatile int dummy{}; return sin; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static std::atomic<MySingleton*> instance; static std::mutex myMutex; }; std::atomic<MySingleton*> MySingleton::instance; std::mutex MySingleton::myMutex;
Maybe you heard that the double-checked locking pattern is broken. Of course, not my implementation! If you don’t believe me, prove it to me. First, you have to study the memory model, think about the acquire-release semantic, and think about the synchronization and ordering constraint that will hold in this implementation. This is not an easy job. But you know, highly sophisticated code pays off.
Damn. I forgot the rule Per.6: Here are the performance numbers for the Meyers singleton on Linux. I compiled the program with maximum optimization. The numbers on Windows were in the same ballpark.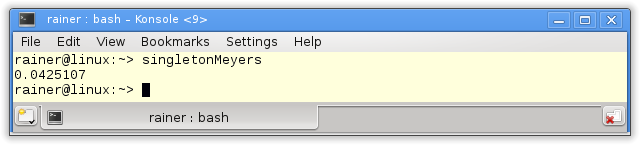
Now I’m curious. What are the numbers for my highly sophisticated code? Let’s see which performance we will get with atomics.
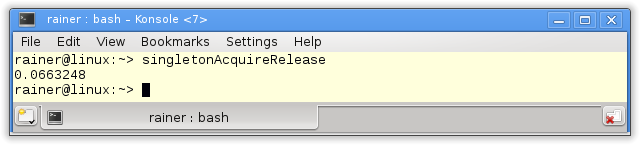
50% percent slower! 50% percent slower, and we don’t even know if the implementation is correct. Disclaimer: The implementation is correct.
Indeed, the Meyers singleton was the fastest and easiest way to get a thread-safe implementation of the singleton pattern. If you are curious about the details, read my post: Thread-safe initialization of a singleton.
What’s next?
There are more than 10 rules to performance left in the guidelines. Although it is quite challenging to write about such general rules for my next post, I have a few ideas in mind.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, and Honey Sukesan.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org
Modernes C++ Mentoring,







Leave a Reply
Want to join the discussion?Feel free to contribute!