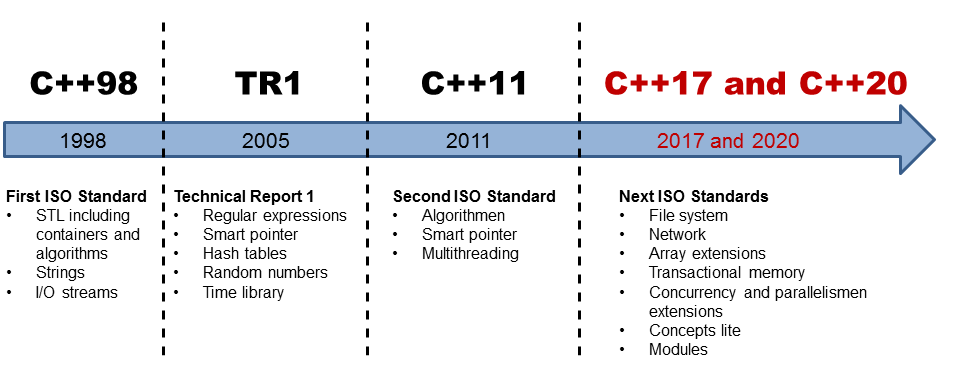
C++17: New Parallel Algorithms of the Standard Template Library
The idea is quite simple. The Standard Template (STL) has more than 100 algorithms for searching, counting, and manipulating ranges and their elements. With C++17, 69 are overloaded, and a few new ones are added. The overloaded and new algorithm can be invoked with a so-called execution policy. By using the execution policy, you can specify whether the algorithm should run sequentially, parallel, or parallel and vectorized.
My previous post was mainly about overloaded algorithms. If you are curious, read the post Parallel Algorithm of the Standard Template Library.
Today, I’m writing about the seven new algorithms. Here are they.
std::for_each_n std::exclusive_scan std::inclusive_scan std::transform_exclusive_scan std::transform_inclusive_scan std::parallel::reduce std::parallel::transform_reduce
Besides std::for_each_n these names are pretty unusual. So let me make a short detour and write about Haskell.
A short detour
To make the long story short. All new functions have a pendant in the pure functional language Haskell.
- for_each_n is called map in Haskell.
- exclusive_scan and inclusive_scan are called scanl and scanl1 in Haskell.
- transform_exclusive_scan and transform_inclusive_scan is a composition of the Haskell functions map and scanl or scanl1.
- reduce is called foldl or foldl1 in Haskell.
- transform_reduce is a composition of the Haskell functions map and foldl or foldl1.
Before I show you Haskell in action, let me describe the different functions.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
- map applies a function to a list.
- foldl and foldl1 apply a binary operation to a list and reduces the list to a value. foldl needs contrary to foldl1 an initial value.
- scanl and scanl1 apply the same strategy such as foldl and foldl1, but they produce all intermediate values. So you get back a list.
- foldl, foldl1, scanl, and scanl1 start their job from the left.
Now comes the action. Here is Haskell’s interpreter shell.
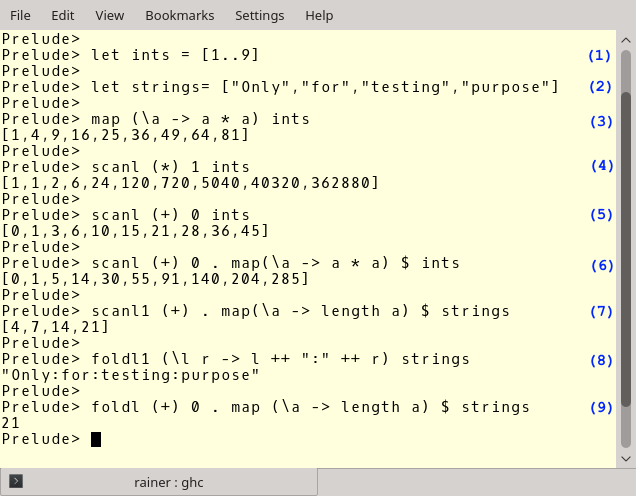
(1) and (2) define a list of integers and a list of strings. In (3), I apply the lambda function (\a -> a * a) to the list of ints. (4) and (5) are more sophisticated. The expression (4) multiplies (*) all pairs of integers, starting with 1 as a neutral multiplication element. Expression (5) does the corresponding for the addition. The expressions (6), (7), and (9) are quite challenging to read for the imperative eye. You have to read them from right to left. scanl1 (+) . map(\a -> length a (7) is a function composition. The dot (.) symbol composes the two functions. The first function maps each element to its length. The second function adds the list of lengths together. (9) is similar to 7. The difference is that foldl produces one value and requires an initial element. This is 0. Now, the expression (8) should be readable. The expression successively joins two strings with the “:” character.
You wonder why I write in a C++ blog so much challenging stuff about Haskell. That is for two good reasons. First, you know the history of C++ functions. And second, it’s a lot easier to understand the C++ function if you compare them with the Haskell pendants.
So, let’s finally start with C++.
The seven new algorithms
I promised it may become a little bit difficult to read.
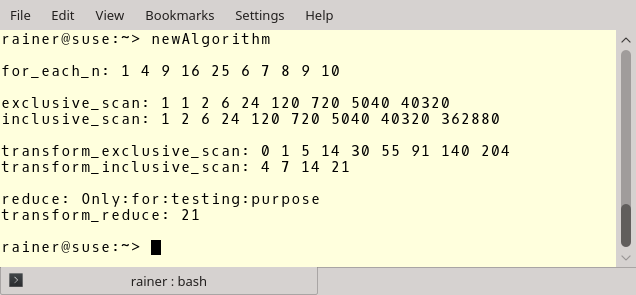
// newAlgorithm.cpp #include <hpx/hpx_init.hpp> #include <hpx/hpx.hpp> #include <hpx/include/parallel_numeric.hpp> #include <hpx/include/parallel_algorithm.hpp> #include <hpx/include/iostreams.hpp> #include <string> #include <vector> int hpx_main(){ hpx::cout << hpx::endl; // for_each_n std::vector<int> intVec{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // 1 hpx::parallel::for_each_n(hpx::parallel::execution::par, // 2 intVec.begin(), 5, [](int& arg){ arg *= arg; }); hpx::cout << "for_each_n: "; for (auto v: intVec) hpx::cout << v << " "; hpx::cout << "\n\n"; // exclusive_scan and inclusive_scan std::vector<int> resVec{1, 2, 3, 4, 5, 6, 7, 8, 9}; hpx::parallel::exclusive_scan(hpx::parallel::execution::par, // 3 resVec.begin(), resVec.end(), resVec.begin(), 1, [](int fir, int sec){ return fir * sec; }); hpx::cout << "exclusive_scan: "; for (auto v: resVec) hpx::cout << v << " "; hpx::cout << hpx::endl; std::vector<int> resVec2{1, 2, 3, 4, 5, 6, 7, 8, 9}; hpx::parallel::inclusive_scan(hpx::parallel::execution::par, // 5 resVec2.begin(), resVec2.end(), resVec2.begin(), [](int fir, int sec){ return fir * sec; }, 1); hpx::cout << "inclusive_scan: "; for (auto v: resVec2) hpx::cout << v << " "; hpx::cout << "\n\n"; // transform_exclusive_scan and transform_inclusive_scan std::vector<int> resVec3{1, 2, 3, 4, 5, 6, 7, 8, 9}; std::vector<int> resVec4(resVec3.size()); hpx::parallel::transform_exclusive_scan(hpx::parallel::execution::par, // 6 resVec3.begin(), resVec3.end(), resVec4.begin(), 0, [](int fir, int sec){ return fir + sec; }, [](int arg){ return arg *= arg; }); hpx::cout << "transform_exclusive_scan: "; for (auto v: resVec4) hpx::cout << v << " "; hpx::cout << hpx::endl; std::vector<std::string> strVec{"Only","for","testing","purpose"}; // 7 std::vector<int> resVec5(strVec.size()); hpx::parallel::transform_inclusive_scan(hpx::parallel::execution::par, // 8 strVec.begin(), strVec.end(), resVec5.begin(), 0, [](auto fir, auto sec){ return fir + sec; }, [](auto s){ return s.length(); }); hpx::cout << "transform_inclusive_scan: "; for (auto v: resVec5) hpx::cout << v << " "; hpx::cout << "\n\n"; // reduce and transform_reduce std::vector<std::string> strVec2{"Only","for","testing","purpose"}; std::string res = hpx::parallel::reduce(hpx::parallel::execution::par, // 9 strVec2.begin() + 1, strVec2.end(), strVec2[0], [](auto fir, auto sec){ return fir + ":" + sec; }); hpx::cout << "reduce: " << res << hpx::endl; // 11 std::size_t res7 = hpx::parallel::parallel::transform_reduce(hpx::parallel::execution::par, strVec2.begin(), strVec2.end(), [](std::string s){ return s.length(); }, 0, [](std::size_t a, std::size_t b){ return a + b; }); hpx::cout << "transform_reduce: " << res7 << hpx::endl; hpx::cout << hpx::endl; return hpx::finalize(); } int main(int argc, char* argv[]){ // By default this should run on all available cores std::vector<std::string> const cfg = {"hpx.os_threads=all"}; // Initialize and run HPX return hpx::init(argc, argv, cfg); }
Before I show you the program’s output and explain the source code, I must make a general remark. As far as I know, no parallel STL implementation is available. Therefore, I used the HPX implementation that uses the namespace hpx. So, if you replace the namespace hpx with std and write the code in the hpx_main function, you know what the STL algorithm will look like.
In correspondence to Haskell, I use a std::vector of ints (1) and strings (7).
The for_each_n algorithm in (2) maps the first n ints of the vector to its power of 2.
exclusive_scan (3) and inclusive_scan (5) are pretty similar. Both apply a binary operation to their elements. The difference is that exclusive_scan excludes in each iteration the last element. You have the corresponding Haskell expression: scanl (*) 1 ints.
The transform_exclusive_scan (6) is quite challenging to read. Let me try it. Apply in the first step the lambda function [](int arg){ return arg *= arg; } to each element of the range from resVec3.begin() to resVec3.end(). Then apply in the second step the binary operation [](int fir, int sec){ return fir + sec; } to the intermediate vector. That means summing up all elements by using 0 as the initial element. The result goes to resVec4.begin(). To make the long story short. Here is Haskell: scanl (+) 0 . map(\a -> a * a) $ ints.
The transform_inclusive_scan function in (8) is similar. This function maps each element to its length. Once more in Haskell: scanl1 (+) . map(\a -> length a) $ strings.
Now, the reduce function should be pretty simple to read. It puts “:” characters between each element of the input vector. The resulting string should not start with a “:” character. Therefore, the range starts at the second element (strVec2.begin() + 1), and the initial element is the first element of the vector: strVec2[0]. Here is Haskell: foldl1 (\l r -> l ++ “:” ++ r) strings.
If you want to understand the transform_reduce expression in (11), please read my post Parallel Algorithm of the Standard Template Library. I have more to say about the function. For the impatient readers. The concise expression in Haskell: foldl (+) 0 . map (\a -> length a) $ strings.
Studying the output of the program should help you.
Final remarks
Each of the seven new algorithms exists in different flavors. You can invoke them with and without an initial element, with and without specifying the execution policy. You can invoke the function that requires a binary operator, such as std::scan and std::parallel::reduce, even without a binary operator. In this case, the addition is used as default. The binary operator must be associative to execute the algorithm in parallel or in parallel and vectorized. That makes excellent sense because the algorithm can efficiently run on many cores. For the details, read the Wikipedia article on prefix_sum. Here are further details about the new algorithms: extensions for parallelism.
What’s next?
Sorry, that was a long post. But making two posts out of it makes no sense. In the next post, I will write about the performance-improved interface of the associative containers (sets and maps) and the unified interface of the STL containers at.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, and Silviu Ardelean.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org







Leave a Reply
Want to join the discussion?Feel free to contribute!