Relaxed Semantics
The relaxed semantics is the end of the scale. The relaxed semantic is the weakest of all memory models and guarantees that the operations on atomic variables are atomic.
No synchronization and ordering constraints
That’s relatively easy. If there are no rules, we can not break them. But that’s too easy. The program should have well-defined behavior. That means, in this case: No race condition. To guarantee this, you typically use synchronization and ordering constraints of stronger memory models to control operations with relaxed semantics. How does this work? A thread can see the effects of another thread in arbitrary order. So, you must only be sure that there are points in your program in which all operations on all threads get synchronized.
A typical example of an atomic operation, in which the sequence of operations doesn’t matter, is a counter. The key of a counter is not, in which order the different threads increment the counter. The key of the counter is that all increments are atomic and all threads are done at the end. Have a look at the example.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// relaxed.cpp #include <vector> #include <iostream> #include <thread> #include <atomic> std::atomic<int> cnt = {0}; void f() { for (int n = 0; n < 1000; ++n) { cnt.fetch_add(1, std::memory_order_relaxed); } } int main() { std::vector<std::thread> v; for (int n = 0; n < 10; ++n) { v.emplace_back(f); } for (auto& t : v) { t.join(); } std::cout << "Final counter value is " << cnt << '\n'; } |
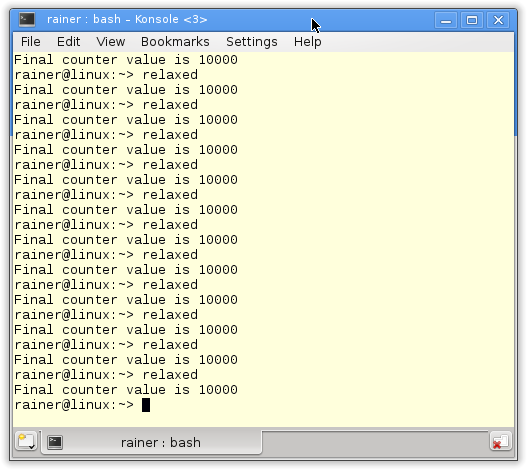
The three most exciting lines are 13, 24, and 26.
In line 13, the atomic number cnt is incremented with relaxed semantics. So, we have the guarantee that the operation is atomic. The fetch_add operation established an ordering on cnt. The function f (lines 10 – 15) is the work package of the threads. Each thread gets its work package in line 21.
Thread creation is one synchronization point. The other synchronization point is the t.join() call in line 24.
The creator thread synchronizes with all its children in line 24. It waits with the t.join() call until all its children are done. t.join() is the reason that the results of the atomic operations are published. To say it more formally: t.join() is a release operation.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
In the end, there is a happen-before relation between the increment operation in line 13 and the reading of the counter cnt in line 26.
The result is, that the program always returns 10000. Boring? No, calming!
A typical example of an atomic counter using the relaxed semantic is the reference counter of std::shared_ptr. That will only hold for the increment operation. The key for incrementing the reference counter is that the operation is atomic. The order of the increment operations does not matter. That will not hold for the decrementation of the reference counter. These operations need an acquire-release semantic with the destructor.
I want to explicitly say thanks to Anthony Williams, author of the well-known book C++ Concurrency in Action. He gave me very valuable tips for this post. Anthony writes his blog to concurrency in modern C++: https://www.justsoftwaresolutions.co.uk/blog/.
Business before pleasure
Business before pleasure. That’s my simple motto for the next posts. So, I will use the theory about atomics and the memory model in practice.
int x= 0; int y= 0; void writing(){ x= 2000; y= 11; } void reading(){ std::cout << "y: " << y << " "; std::cout << "x: " << x << std::endl; } int main(){ std::thread thread1(writing); std:.thread thread2(reading); thread1.join(); thread2.join(); };
What’s next?
The program looks quite simple. But it has undefined behavior. Why? I will answer the question in the following post. But that is only the first step. I want to optimize the program. If you want to play with atomics and the memory model, it’s always a good idea to have a static code analyzer at your disposal. So, in the next post, I will introduce the invaluable, precious tool CppMem.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, and Seeker.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org






Leave a Reply
Want to join the discussion?Feel free to contribute!