Blocking and Non-Blocking Algorithms
Blocking, non-blocking, lock-free, and wait-free. Each of these terms describes a key characteristic of an algorithm when executed in a concurrent environment. So, reasoning about the runtime behavior of your program often means putting your algorithm in the right bucket. Therefore, this post is about buckets.
An algorithm fall into one of two buckets: blocking or non-blocking.
Let’s first talk about blocking.
Blocking
Intuitively, it is quite clear what blocking for an algorithm mean. But concurrency is not about intuition, it’s about precise terms. The easiest way to define blocking is to define it with the help of non-blocking.
- Non-blocking: An algorithm is called non-blocking if the failure or suspension of any thread cannot cause the failure or suspension of another thread. (Java concurrency in practice)
There is not any word about locking in this definition. That’s right. Non-blocking is a broader term.
To block a program is relatively easy. The typical use case is to use more than one mutex and lock them in a different sequence. Nice timing, and you have a deadlock. But there are a lot more ways to produce blocking behavior.
Each time you have to wait for a resource, a block is possible.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Here are a few examples for synchronizing access to a resource:
- A condition variable with wait.
- A future with wait or get.
Even the join call of a thread can be used to block a thread.
// deadlockWait.cpp #include <iostream> #include <mutex> #include <string> #include <thread> std::mutex coutMutex; int main(){ std::thread t([]{ std::cout << "Still waiting ..." << std::endl; // 2 std::lock_guard<std::mutex> lockGuard(coutMutex); // 3 std::cout << "child: " << std::this_thread::get_id() << std::endl;} ); { std::lock_guard<std::mutex> lockGuard(coutMutex); // 1 std::cout << "creator: " << std::this_thread::get_id() << std::endl; t.join(); // 5 } // 4 }
The program run will block immediately.
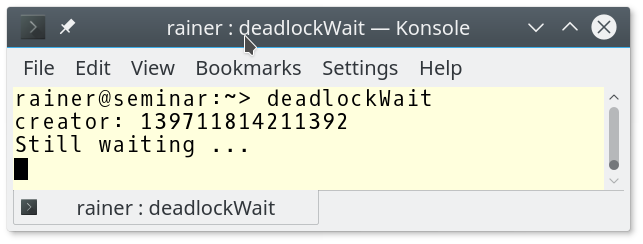
What is happening? The creator thread locks in (1) the mutex. Now, the child thread executes (2). To get the mutex in expression (3), the creator thread has at first to unlock it. But the creator thread will only unlock the mutex if the lockGuard (1) goes in (4) out of scope. That will never happen because the child thread has at first to lock the mutex coutMutex.
Let’s have a look at the non-blocking algorithms.
Non-blocking
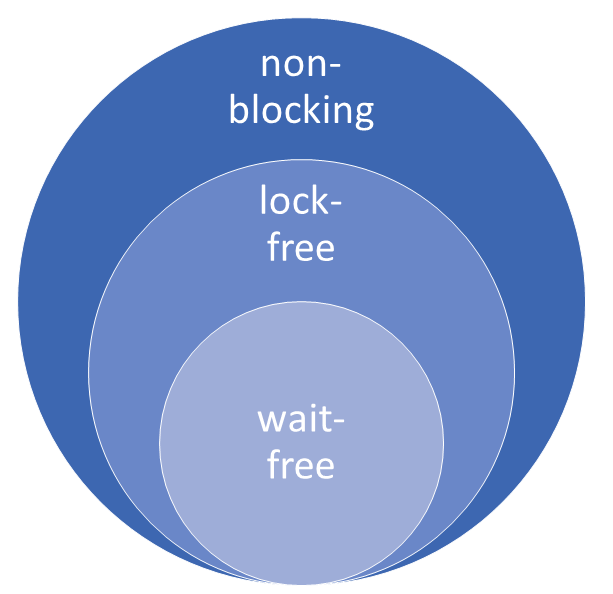
The main categories for non-blocking algorithms are lock-free and wait-free. Each wait-free algorithm is lock-free, and each lock-free is non-blocking. Non-blocking and lock-free are not the same. There is an additional guarantee called obstruction-free, which I will ignore in this post because it is not so relevant.
Non-blocking algorithms are typically implemented with CAS instructions. CAS stands for compare and swap. CAS is called compare_exchange_strong or compare_exchange_weak in C++.
I will in this post only refer to the strong version. For more information, read my previous post The Atomic Boolean. The key idea of both operations is a call of atomicValue.compare_exchange_strong(expected, desired) obeys the following rules in an atomic fashion.
- If the atomic comparison of atomicValue with expected returns true, atomicValue will be set in the same atomic operation as desired.
- If the comparison returns false, expected will be set to atomicValue.
Let’s now have a closer look at lock-free versus wait-free.
At first, the definition of lock-free and wait-free. Both definitions are quite similar. Therefore, it makes a lot of sense to define them together.
- Lock-free: A non-blocking algorithm is lock-free if there is guaranteed system-wide progress.
- Wait-free: A non-blocking algorithm is wait-free if there is guaranteed per-thread progress.
Lock-free
// fetch_mult.cpp #include <atomic> #include <iostream> template <typename T> T fetch_mult(std::atomic<T>& shared, T mult){ // 1 T oldValue = shared.load(); // 2 while (!shared.compare_exchange_strong(oldValue, oldValue * mult)); // 3 return oldValue; } int main(){ std::atomic<int> myInt{5}; std::cout << myInt << std::endl; fetch_mult(myInt,5); std::cout << myInt << std::endl; }
The algorithm fetch_mult (1) multiplies an std::atomic shared by mult. The critical observation is that there is a small time window between the reading of the old value T oldValue = shared Load (2) and the comparison with the new value (3). Therefore, another thread can always kick in and change the oldValue. If you reason about such a bad interleaving of threads, you see that there can be no per-thread progress guarantee.
Therefore, the algorithm is lock-free but not wait-free.
Here is the output of the program.

While a lock-free algorithm guarantees system-wide progress, a wait-free algorithm guarantees per-thread progress.
Wait-free
You will see if you reason about the lock-free algorithm in the last example. A compare_exchange_strong call involves synchronization. First, you read the old value, and then update the new value if the initial condition already holds. If the initial condition holds, you publish the new value. If not, you do it again if you put the call in a while loop. Therefore compare_exchange_strong behaves like an atomic transaction.
The crucial part of the following program needs no synchronization.
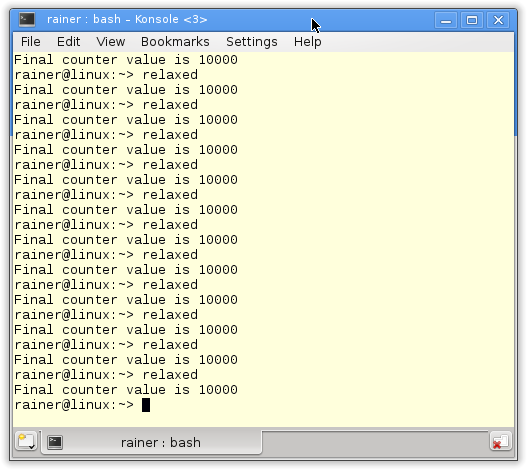
// relaxed.cpp #include <vector> #include <iostream> #include <thread> #include <atomic> std::atomic<int> cnt = {0}; void add(){ // 1 for (int n = 0; n < 1000; ++n) { cnt.fetch_add(1, std::memory_order_relaxed); // 2 } } int main() { std::vector<std::thread> v; for (int n = 0; n < 10; ++n) { v.emplace_back(add); } for (auto& t : v) { t.join(); } std::cout << "Final counter value is " << cnt << '\n'; }
Have a closer look at function add (1). There is no synchronization involved in expression (2). The value 1 is just added to the atomic cnt.
And here is the output of the program. We always get 10000 because 10 threads increment the value 1000 times.
For simplicity reasons, I ignored a few other guarantees in this post, such as starvation-free as a subset of blocking or wait-free bounded as a subset of wait-free. You can read the details on the blog Concurrency Freaks.
What’s next?
In the next post, I will write about curiosity. The so-called ABA problem is a kind of false-positive case for CAS instructions. That means although the old value of a CAS instruction is still the same, it changed in the meantime.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org




Leave a Reply
Want to join the discussion?Feel free to contribute!